| Commit message (Collapse) | Author | Age | Files | Lines |
|---|
| ... | |
| |\ \ \ \ \ \ \ \
| |_|/ / / / / /
|/| | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4950: Use correct substs for super trait assoc types r=matklad a=flodiebold
When referring to an associated type of a super trait, we used the substs of the
subtrait. That led to the #4931 crash if the subtrait had less parameters, but
it could also lead to other incorrectness if just the order was different.
Fixes #4931.
Co-authored-by: Florian Diebold <[email protected]>
|
| |/ / / / / / /
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
When referring to an associated type of a super trait, we used the substs of the
subtrait. That led to the #4931 crash if the subtrait had less parameters, but
it could also lead to other incorrectness if just the order was different.
Fixes #4931.
|
| |\ \ \ \ \ \ \
| |/ / / / / /
|/| | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
4957: Fix substs in resolve_value_path for ImplSelf r=flodiebold a=Speedy37
Fixes #4953.
This is the first fix I do in hir_ty, I hope I got it right :)
Co-authored-by: Vincent Rouillé <[email protected]>
|
| |/ / / / / /
| | | | | |
| | | | | |
| | | | | | |
Fixes #4953.
|
| |\ \ \ \ \ \
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
4851: Add quickfix to add a struct field r=TimoFreiberg a=TimoFreiberg
Related to #4563
I created a quickfix for record literals first because the NoSuchField diagnostic was already there.
To offer that quickfix for FieldExprs with unknown fields I'd need to add a new diagnostic (or create a `NoSuchField` diagnostic for those cases)
I think it'd make sense to make this a snippet completion (to select the generated type), but this would require changing the `Analysis` API and I'd like some feedback before I touch that.
Co-authored-by: Timo Freiberg <[email protected]>
|
| | | | | | | | |
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4937: Allow overriding rust-analyzer display version r=matklad a=oxalica
The build script invokes `git` for version information which is displayed when rust-analyzer is called with `--version`. But in build environment without `git` or when the source code is not a git repo, there's no way to manually specify the version information.
This patch respects environment variable ~`REV`~ `RUST_ANALYZER_REV` in compile time for overriding.
Related: https://github.com/NixOS/nixpkgs/pull/90976
Co-authored-by: oxalica <[email protected]>
|
| | | | | | | | | |
|
| | | |_|_|_|_|/
| |/| | | | | |
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4839: `Go to Type Definition` hover action. r=matklad a=vsrs
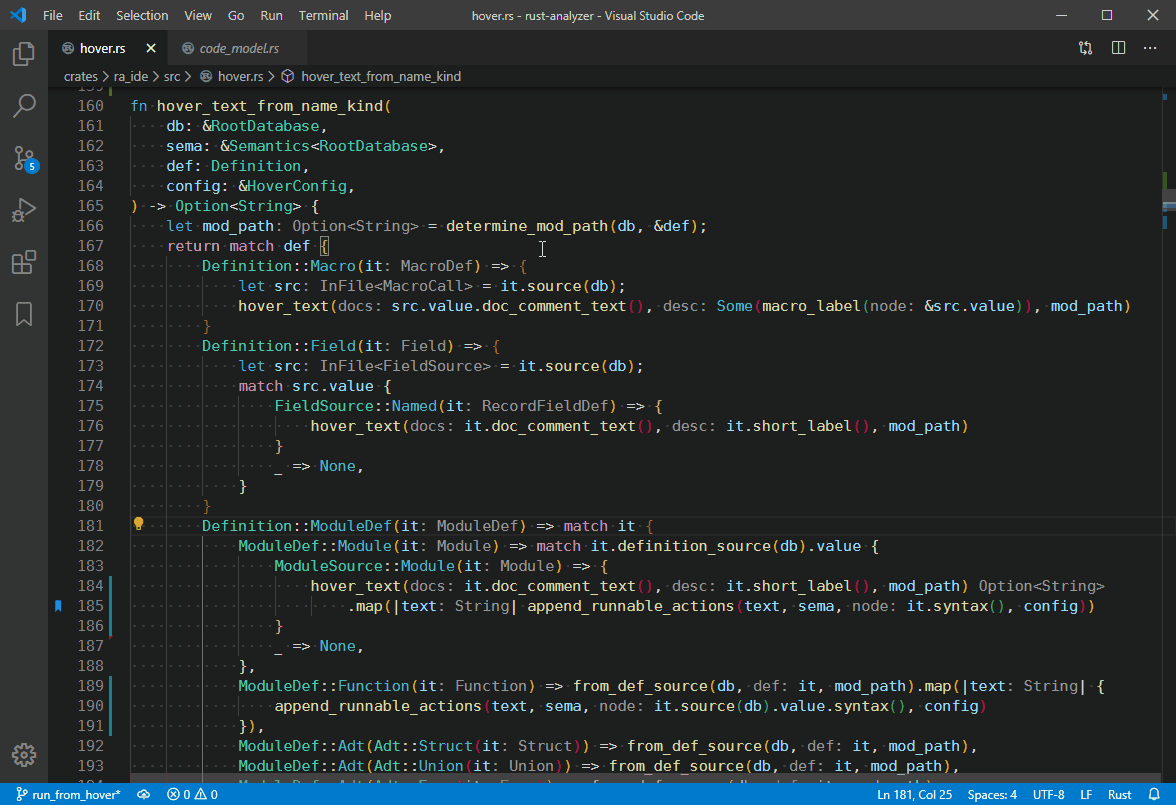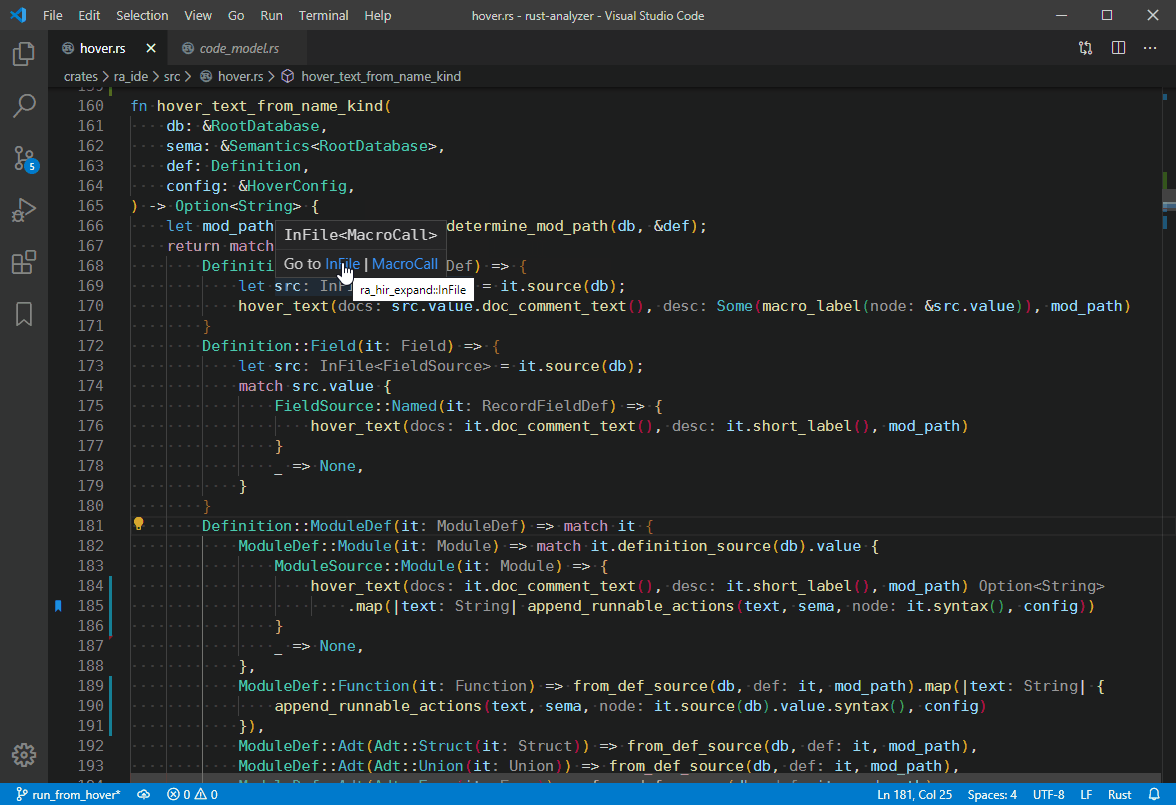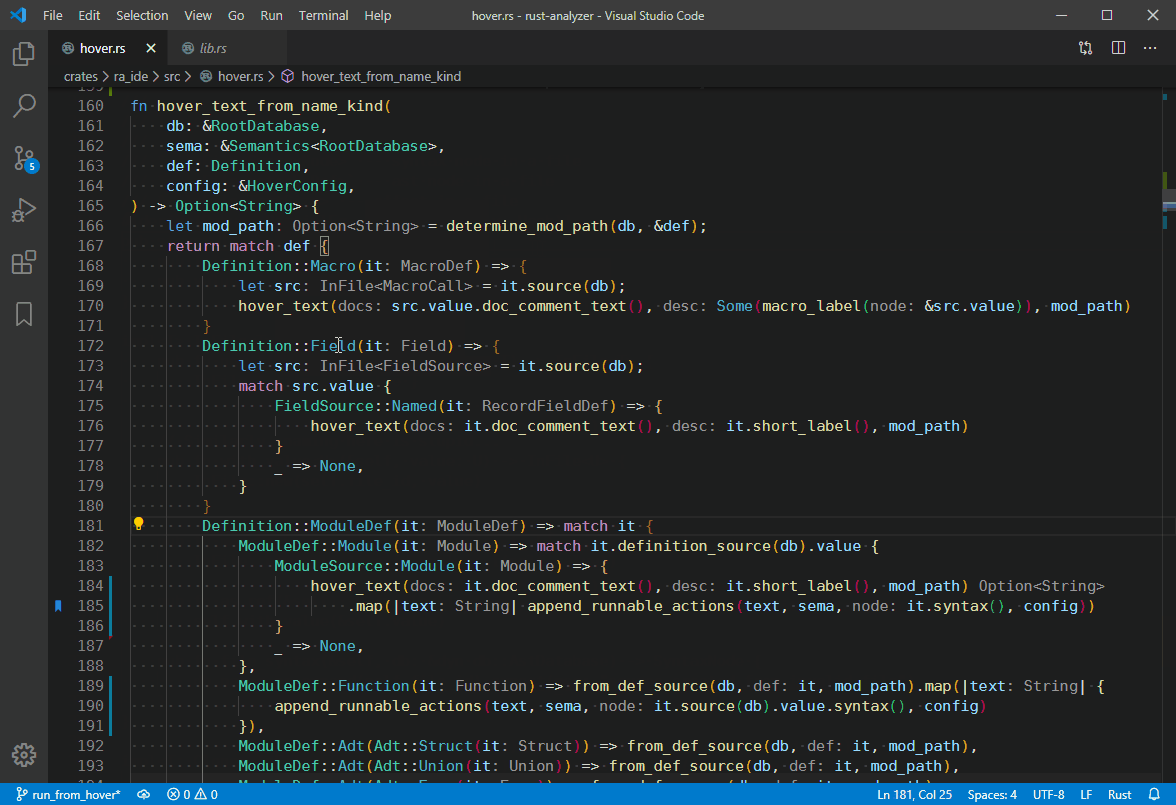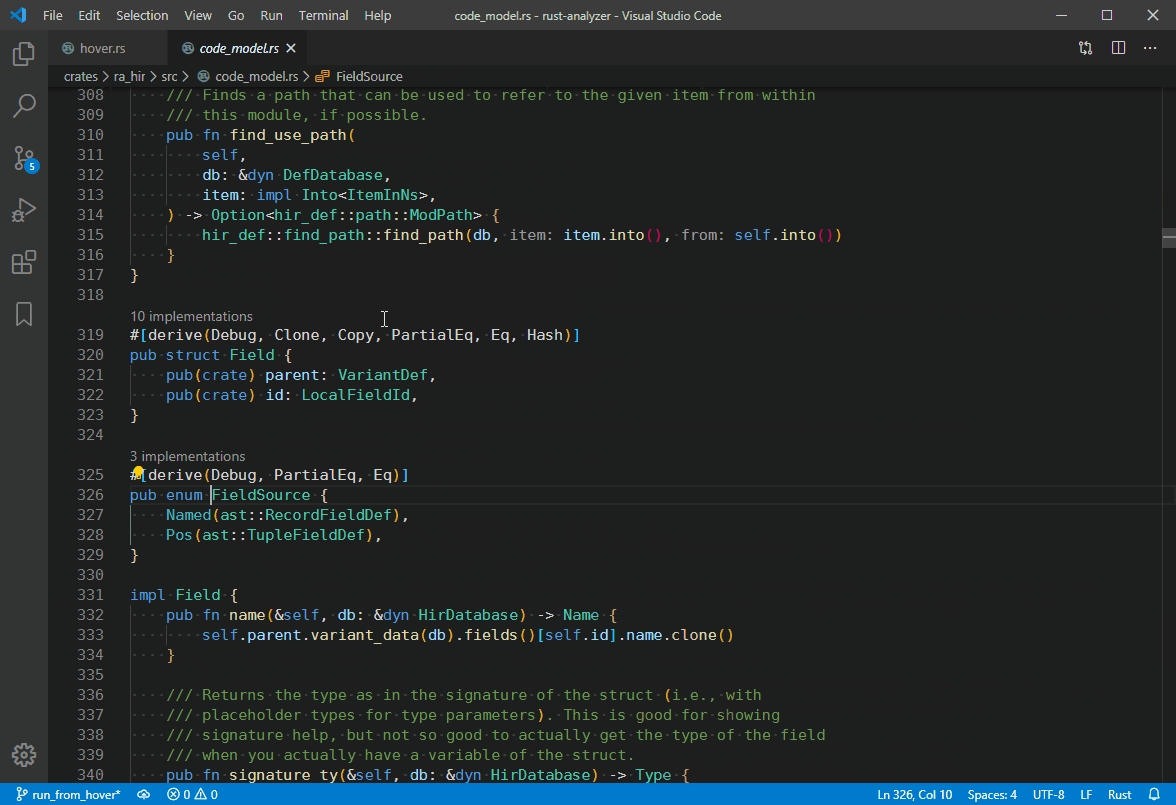
This implementation supports things like `dyn Trait<SomeType>`, `-> impl Trait`, etc.
Co-authored-by: vsrs <[email protected]>
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| | | | | | | | | |
|
| |\ \ \ \ \ \ \ \
| |_|_|_|/ / / /
|/| | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4948: Speedup VFS::partition r=matklad a=matklad
The task of `partition` function is to bin the flat list of paths into
disjoint filesets. Ideally, it should be incremental -- each new file
should be added to a specific fileset.
However, preliminary measurnments show that it is actually fast enough
if we just optimize this to use a binary search instead of a linear
scan.
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| |/ / / / / / /
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
The task of `partition` function is to bin the flat list of paths into
disjoint filesets. Ideally, it should be incremental -- each new file
should be added to a specific fileset.
However, preliminary measurnments show that it is actually fast enough
if we just optimize this to use a binary search instead of a linear
scan.
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4930: Avoid all unchecked indexing in match checking r=flodiebold a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/4416, but replaces it with a false positive.
r? @flodiebold
Co-authored-by: Jonas Schievink <[email protected]>
|
| | | |_|_|/ / /
| |/| | | | | |
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4941: Simplify r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| | | |_|/ / / /
| |/| | | | | |
|
| |\ \ \ \ \ \ \
| |/ / / / / /
|/| | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
4903: Add highlighting support for doc comments r=matklad a=Nashenas88
The language server protocol includes a semantic modifier for documentation. This change exports that modifier for doc comments so users can choose to highlight them differently compared to regular comments.
Example:
<img width="375" alt="Screen Shot 2020-06-16 at 10 34 14 AM" src="https://user-images.githubusercontent.com/1673130/84788271-f6599580-afbc-11ea-96e5-7a0215da620b.png">
CC @woody77
Co-authored-by: Paul Daniel Faria <[email protected]>
|
| | | | | | | | |
|
| | | | | | | | |
|
| | | | | | | | |
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4935: Simplify r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| | | |_|/ / / /
| |/| | | | | |
|
| |\ \ \ \ \ \ \
| |/ / / / / /
|/| | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
4821: display Doctest code lens before comment r=matklad a=bnjjj
close #4785
Co-authored-by: Benjamin Coenen <[email protected]>
|
| | | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
Signed-off-by: Benjamin Coenen <[email protected]>
|
| | | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
Signed-off-by: Benjamin Coenen <[email protected]>
|
| | | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
Signed-off-by: Benjamin Coenen <[email protected]>
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4872: Reduce the usage of bare subscript operator r=matklad a=Veetaha
Co-authored-by: Veetaha <[email protected]>
|
| | | | | | | | | |
|
| |\ \ \ \ \ \ \ \
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | | |
4934: Remove special casing for library symbols r=matklad a=matklad
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| | | |_|_|/ / / /
| |/| | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
|
| |\ \ \ \ \ \ \ \
| |/ / / / / / /
|/| | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4932: Simplify r=matklad a=Veetaha
Co-authored-by: Veetaha <[email protected]>
|
| |/ / / / / / / |
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4927: Better encapsulate reverse-mapping of files to cargo targets r=matklad a=matklad
We need to find a better way to do it...
CrateGraph by itself is fine, CargoWorkspace as well, but the mapping
between the two seems arbitrary...
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| | | |_|/ / / /
| |/| | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
We need to find a better way to do it...
CrateGraph by itself is fine, CargoWorkspace as well, but the mapping
between the two seems arbitrary...
|
| |\ \ \ \ \ \ \
| |/ / / / / /
|/| | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
4925: Syntax highlighting for escape sequences in strings r=matklad a=ltentrup
I have added a new semantic token type `ESCAPE_SEQUENCE` as the LSP specification does not seem to have an appropriate token type. This may actually be a regression for some users, as the TextMate Rust grammar has a scope `constant.character.escape.rust` which highlights escape sequences (which caused problems with semantic highlighting, see #4138).
Fixes #2604.
Co-authored-by: Leander Tentrup <[email protected]>
|
| |/ / / / / / |
|
| | | | | | | | |
| | \ \ \ \ \ | |
| | \ \ \ \ \ | |
| | \ \ \ \ \ | |
| |\ \ \ \ \ \ \ \
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | | |
4913: Remove debugging code for incremental sync r=matklad a=lnicola
4915: Inspect markdown code fences to determine whether to apply syntax highlighting r=matklad a=ltentrup
Fixes #4904
4916: Warnings as hint or info r=matklad a=GabbeV
Fixes #4229
This PR is my second attempt at providing a solution to the above issue. My last PR(#4721) had to be rolled back(#4862) due to it overriding behavior many users expected. This PR solves a broader problem while trying to minimize surprises for the users.
### Problem description
The underlying problem this PR tries to solve is the mismatch between [Rustc lint levels](https://doc.rust-lang.org/rustc/lints/levels.html) and [LSP diagnostic severity](https://microsoft.github.io/language-server-protocol/specification#diagnostic). Rustc currently doesn't have a lint level less severe than warning forcing the user to disable warnings if they think they get to noisy. LSP however provides two severitys below warning, information and hint. This allows editors like VSCode to provide more fine grained control over how prominently to show different diagnostics.
Info severity shows a blue squiggly underline in code and can be filtered separately from errors and warnings in the problems panel.


Hint severity doesn't show up in the problems panel at all and only show three dots under the affected code or just faded text if the diagnostic also has the unnecessary tag.
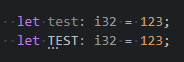
### Solution
The solution provided by this PR allows the user to configure lists of of warnings to report as info severity and hint severity respectively. I purposefully only convert warnings and not errors as i believe it's a good idea to have the editor show the same severity as the compiler as much as possible.

### Open questions
#### Discoverability
How do we teach this to new and existing users? Should a section be added to the user manual? If so where and what should it say?
#### Defaults
Other languages such as TypeScript report unused code as hint by default. Should rust-analyzer similarly report some problems as hint/info by default?
Co-authored-by: Laurențiu Nicola <[email protected]>
Co-authored-by: Leander Tentrup <[email protected]>
Co-authored-by: Gabriel Valfridsson <[email protected]>
|
| | | | | | | | | | |
|
| | | |/ / / / / / |
|
| | |/ / / / / / |
|
| |\ \ \ \ \ \ \
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | | |
4914: Fix panic in match checking r=flodiebold a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/4416
Co-authored-by: Jonas Schievink <[email protected]>
|
