| Commit message (Collapse) | Author | Age | Files | Lines |
|---|
| | |
|
| |\
| |
| |
| |
| |
| |
| |
| |
| | |
7997: fix folding range kind r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| |/ |
|
| |\
| |
| |
| |
| |
| |
| |
| |
| | |
7996: Separate `Ty` and `TyKind` like in Chalk r=flodiebold a=flodiebold
Currently `Ty` just wraps `TyKind`, but this allows us to change most
places to already use `intern` / `interned`.
Co-authored-by: Florian Diebold <[email protected]>
|
| |/
|
|
|
| |
Currently `Ty` just wraps `TyKind`, but this allows us to change most
places to already use `intern` / `interned`.
|
| |\
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| | |
7799: Related tests r=matklad a=vsrs
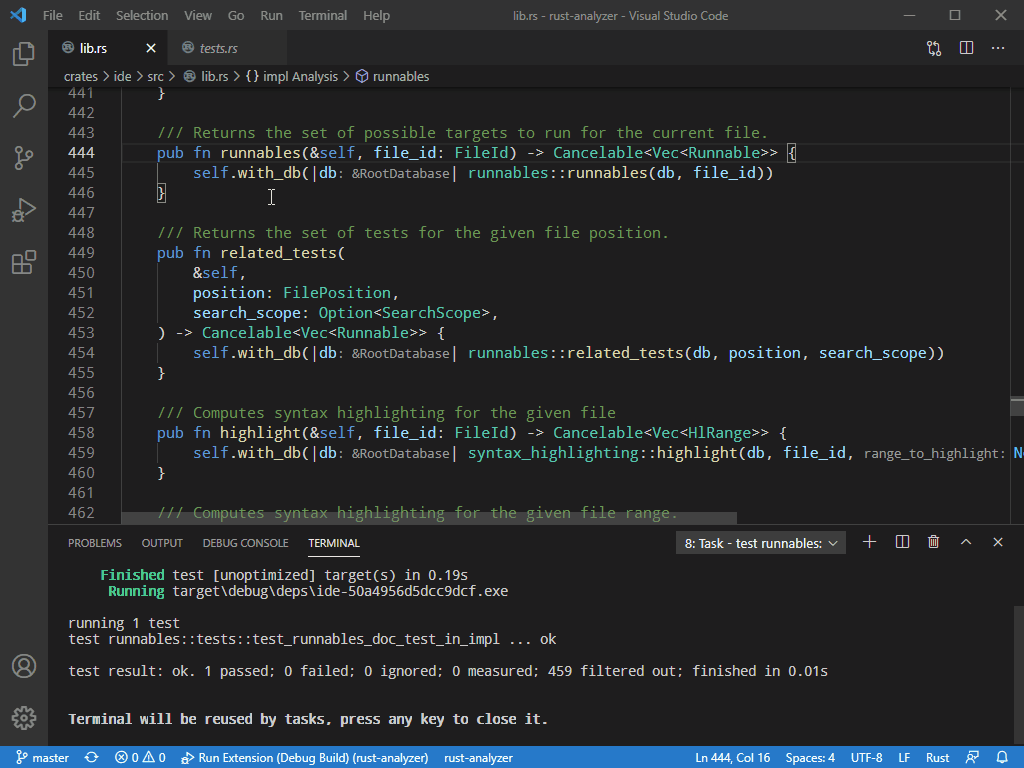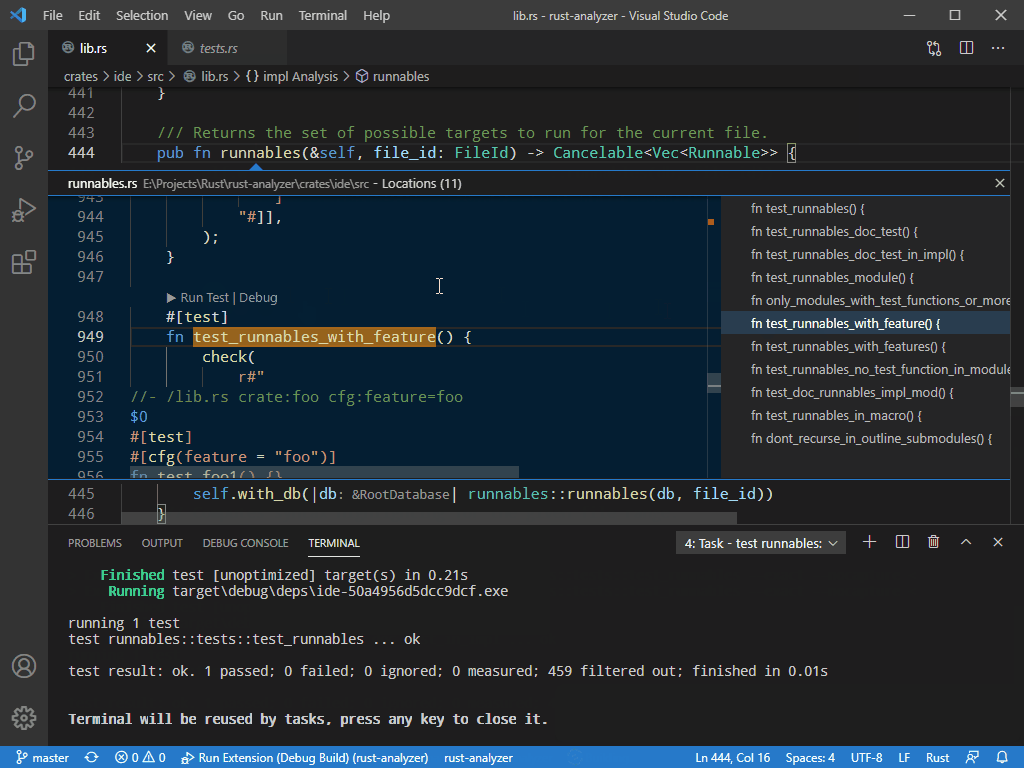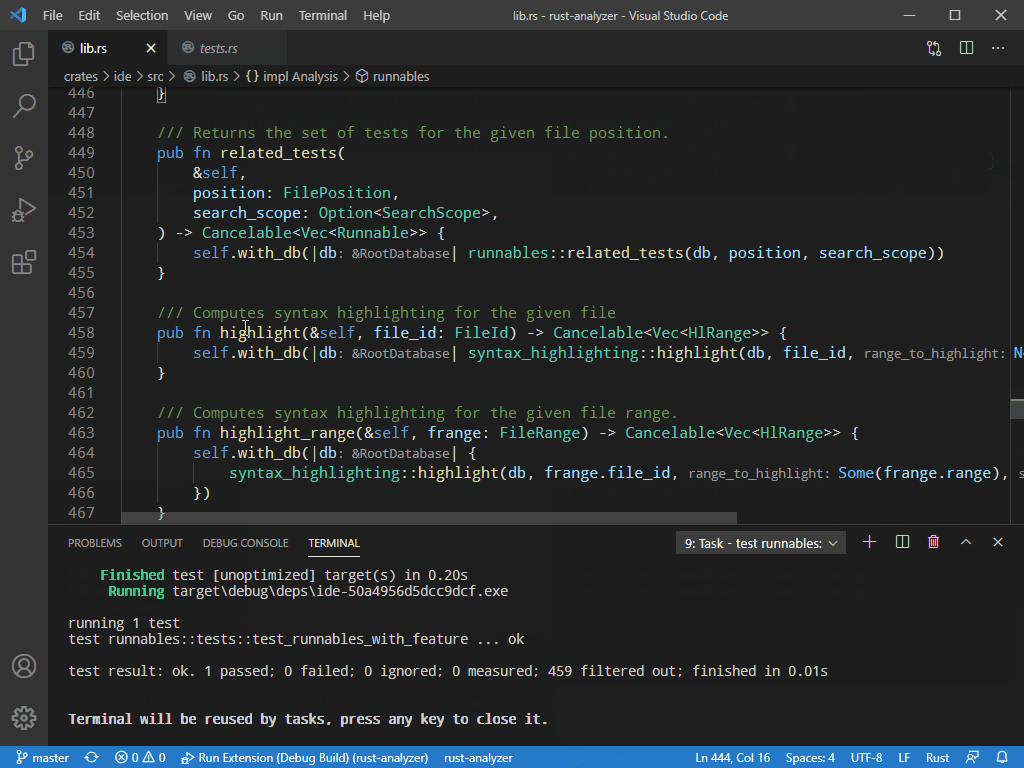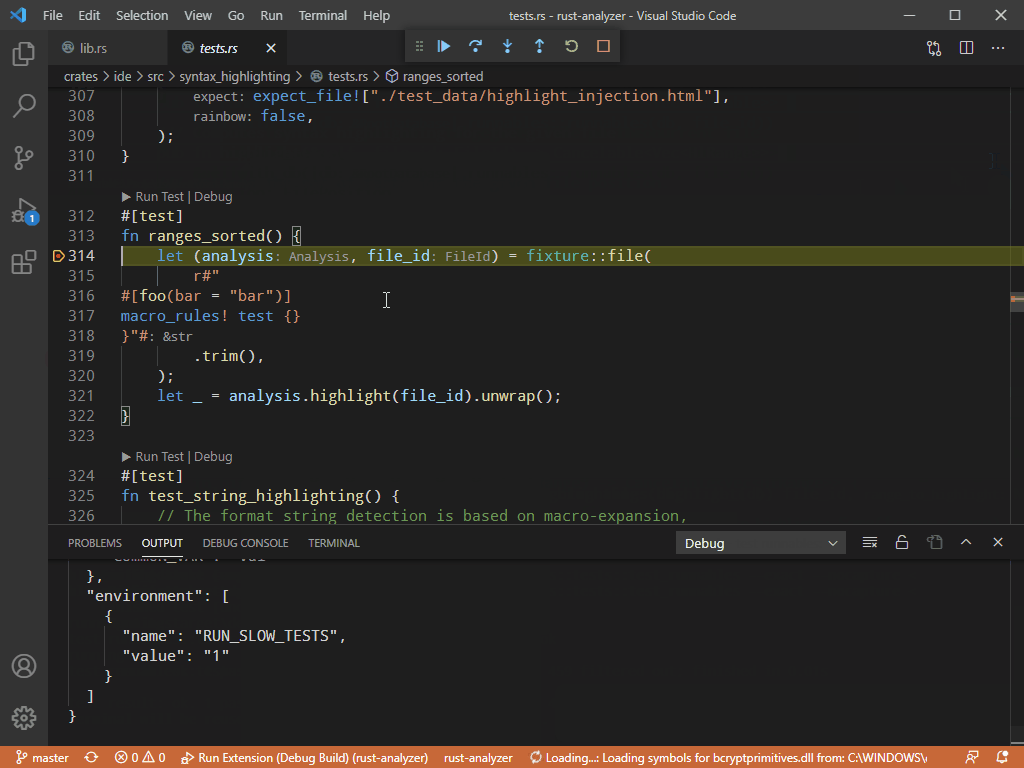
This adds an ability to look for tests for the item under the cursor: function, constant, data type, etc
The LSP part is bound to change. But the feature itself already works and I'm looking for a feedback :)
Co-authored-by: vsrs <[email protected]>
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| |\ \
| | |
| | |
| | |
| | |
| | |
| | |
| | | |
7981: Allow applying De Morgan's law to multiple terms at once r=matklad a=shepmaster
Co-authored-by: Jake Goulding <[email protected]>
|
| | | | |
|
| |\ \ \
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | | |
7984: Improve version display r=matklad a=lnicola
Maybe closes #7854
The version string for unreleased builds looks like this now:
```
$ rust-analyzer --version
rust-analyzer 2021-03-08-159-gc0459c535
```
Release builds should only have the tag name (`2021-03-15`).
Co-authored-by: Laurențiu Nicola <[email protected]>
|
| | |/ / |
|
| |\ \ \
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | | |
7994: Speed up mbe matching in heavy recursive cases r=edwin0cheng a=edwin0cheng
In some cases (e.g. #4186), mbe matching is very slow due to a lot of copy and allocation for bindings, this PR try to solve this problem by introduce a semi "link-list" approach for bindings building.
I used this [test case](https://github.com/weiznich/minimal_example_for_rust_81262) (for `features(32-column-tables)`) to run following command to benchmark:
```
time rust-analyzer analysis-stats --load-output-dirs ./
```
Before this PR : 2 mins
After this PR: 3 seconds.
However, for 64-column-tables cases, we still need 4 mins to complete.
I will try to investigate in the following weeks.
bors r+
Co-authored-by: Edwin Cheng <[email protected]>
|
| | | | | |
|
| | | | | |
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7991: Simplify hir_def TestDB r=jonas-schievink a=jonas-schievink
bors r+
Co-authored-by: Jonas Schievink <[email protected]>
|
| |/ / / / |
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7989: Remove `ItemTree::source` r=jonas-schievink a=jonas-schievink
`HasSource` should be used instead
bors r+
Co-authored-by: Jonas Schievink <[email protected]>
|
| |/ / / /
| | | |
| | | |
| | | | |
`HasSource` should be used instead
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7986: Simplify a bit r=flodiebold a=flodiebold
Co-authored-by: Florian Diebold <[email protected]>
|
| |/ / / / |
|
| |\ \ \ \
| |_|/ /
|/| | |
| | | |
| | | |
| | | |
| | | |
| | | | |
7985: Use Chalk Environment more directly r=flodiebold a=flodiebold
Co-authored-by: Florian Diebold <[email protected]>
|
| |/ / / |
|
| |\ \ \
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | | |
7956: Add assist to convert for_each into for loops r=Veykril a=SaiintBrisson
This PR resolves #7821.
Adds an assist to that converts an `Iterator::for_each` into a for loop:
```rust
fn main() {
let vec = vec![(1, 2), (2, 3), (3, 4)];
x.iter().for_each(|(x, y)| {
println!("x: {}, y: {}", x, y);
})
}
```
becomes
```rust
fn main() {
let vec = vec![(1, 2), (2, 3), (3, 4)];
for (x, y) in x.iter() {
println!("x: {}, y: {}", x, y);
});
}
```
Co-authored-by: Luiz Carlos Mourão Paes de Carvalho <[email protected]>
Co-authored-by: Luiz Carlos <[email protected]>
Co-authored-by: Lukas Wirth <[email protected]>
|
| | | | | |
|
| | | | | |
|
| | | | |
| | | |
| | | | |
Co-authored-by: Lukas Wirth <[email protected]>
|
| | | | | |
|
| | | | | |
|
| | | | | |
|
| | | | | |
|
| | | | | |
|
| | | | | |
|
| | | | | |
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7904: Improved completion sorting r=JoshMcguigan a=JoshMcguigan
I was working on extending #3954 to apply completion scores in more places (I'll have another PR open for that soon) when I discovered that actually completion sorting was not working for me at all in `coc.nvim`. This led me down a bit of a rabbit hole of how coc and vs code each sort completion items.
Before this PR, rust-analyzer was setting the `sortText` field on completion items to `None` if we hadn't applied any completion score for that item, or to the label of the item with a leading whitespace character if we had applied any completion score. Completion score is defined in rust-analyzer as an enum with two variants, `TypeMatch` and `TypeAndNameMatch`.
In vs code the above strategy works, because if `sortText` isn't set [they default it to the label](https://github.com/microsoft/vscode/commit/b4ead4ed665e1ce2e58d8329c682f78da2d4e89d). However, coc [does not do this](https://github.com/neoclide/coc.nvim/blob/e211e361475a38b146a903b9b02343551c6cd372/src/completion/complete.ts#L245).
I was going to file a bug report against coc, but I read the [LSP spec for the `sortText` field](https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion) and I feel like it is ambiguous and coc could claim what they do is a valid interpretation of the spec.
Further, the existing rust-analyzer behavior of prepending a leading whitespace character for completion items with any completion score does not handle sorting `TypeAndNameMatch` completions above `TypeMatch` completions. They were both being treated the same.
The first change this PR makes is to set the `sortText` field to either "1" for `TypeAndNameMatch` completions, "2" for `TypeMatch` completions, or "3" for completions which are neither of those. This change works around the potential ambiguity in the LSP spec and fixes completion sorting for users of coc. It also allows `TypeAndNameMatch` items to be sorted above just `TypeMatch` items (of course both of these will be sorted above completion items without a score).
The second change this PR makes is to use the actual completion scores for ref matches. The existing code ignored the actual score and always assumed these would be a high priority completion item.
#### Before
Here coc just sorts based on how close the items are in the file.

#### After
Here we correctly get `zzz` first, since that is both a type and name match. Then we get `ccc` which is just a type match.
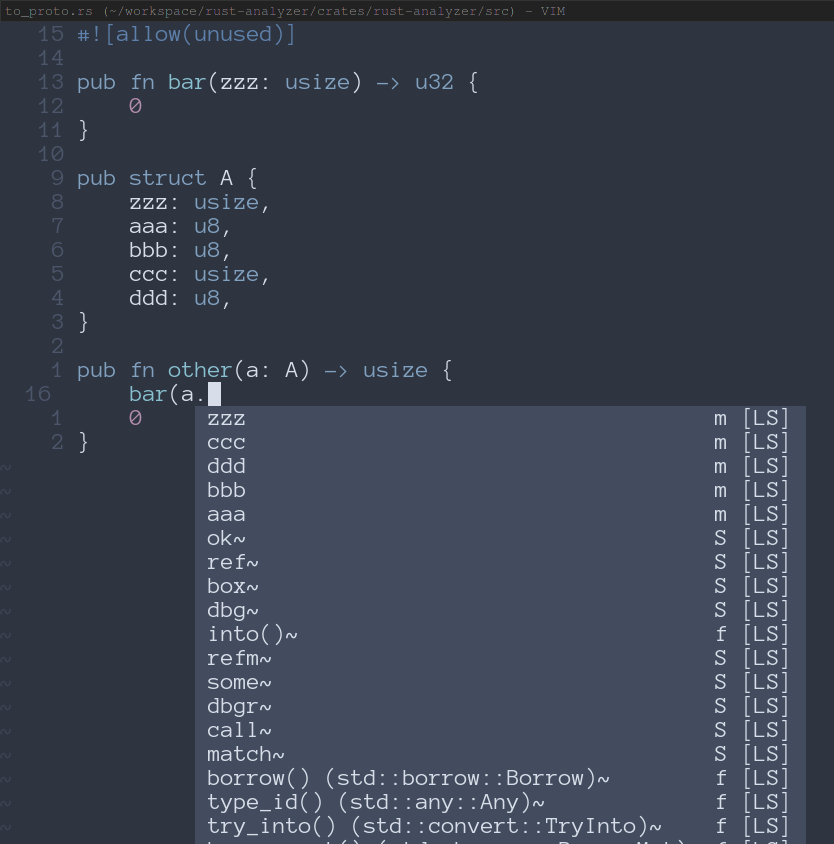
Co-authored-by: Josh Mcguigan <[email protected]>
|
| | | | | | |
|
| | | | | | |
|
| | | | | | |
|
| | | | | | |
|
| |\ \ \ \ \
| |/ / / /
|/| | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7980: Fix remaining references to `cargo xtask codegen` r=matklad a=Veykril
Co-authored-by: Lukas Wirth <[email protected]>
|
| |/ / / / |
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7978: Unify naming r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <[email protected]>
|
| |/ / / / |
|
