| Commit message (Collapse) | Author | Age | Files | Lines |
|---|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| |\
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| | |
8560: Escape characters in doc comments in macros correctly r=jonas-schievink a=ChayimFriedman2
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
Example (the keyword and primitive docs are `include!()`d at https://doc.rust-lang.org/src/std/lib.rs.html#570-578, and thus originate from macro):
Before:
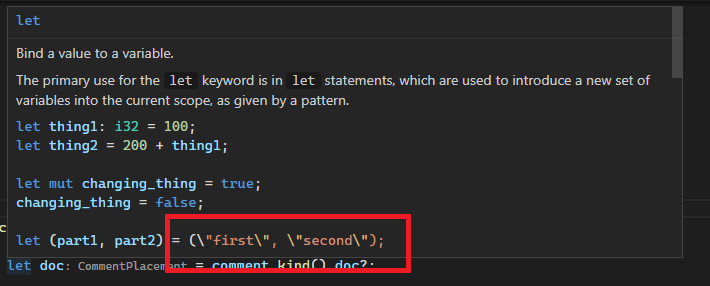
After:
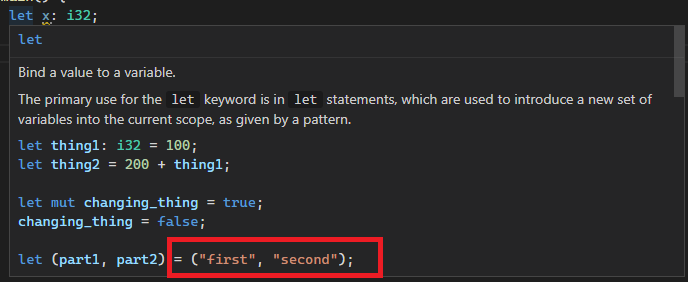
Co-authored-by: Chayim Refael Friedman <[email protected]>
|
| | |
| |
| |
| |
| |
| |
| |
| |
| | |
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
|
| | | |
|
| | |
| |
| |
| | |
It could never return `None`, so reflect that in the return type
|
| | | |
|
| |/ |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| |
|
|
| |
(clippy::unnecessary-unwrap)
|
| |
|
|
| |
example: let x: String = String::from("hello world").into();
|
| | |
|
| | |
|
| |
|
|
|
|
|
| |
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
|
| | |
|
| | |
|
| |\
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| | |
7994: Speed up mbe matching in heavy recursive cases r=edwin0cheng a=edwin0cheng
In some cases (e.g. #4186), mbe matching is very slow due to a lot of copy and allocation for bindings, this PR try to solve this problem by introduce a semi "link-list" approach for bindings building.
I used this [test case](https://github.com/weiznich/minimal_example_for_rust_81262) (for `features(32-column-tables)`) to run following command to benchmark:
```
time rust-analyzer analysis-stats --load-output-dirs ./
```
Before this PR : 2 mins
After this PR: 3 seconds.
However, for 64-column-tables cases, we still need 4 mins to complete.
I will try to investigate in the following weeks.
bors r+
Co-authored-by: Edwin Cheng <[email protected]>
|
| | | |
|
| | | |
|
| |/ |
|
| | |
|
| |\
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| | |
7513: NFA parser for mbe matcher r=matklad a=edwin0cheng
Almost straight porting from rustc one, but a little bit slow :(
```
rust-analyzer analysis-stats -q .
```
From:
```log
Database loaded: 636.11ms, 277minstr
crates: 36, mods: 594, decls: 11527, fns: 9017
Item Collection: 10.99s, 60ginstr
exprs: 249618, ??ty: 2699 (1%), ?ty: 2101 (0%), !ty: 932
Inference: 28.94s, 123ginstr
Total: 39.93s, 184ginstr
```
To:
```log
Database loaded: 630.90ms, 277minstr
crates: 36, mods: 594, decls: 11528, fns: 9018
Item Collection: 13.70s, 77ginstr
exprs: 249482, ??ty: 2699 (1%), ?ty: 2101 (0%), !ty: 932
Inference: 30.27s, 133ginstr
Total: 43.97s, 211ginstr
```
Fixes #4777
Co-authored-by: Edwin Cheng <[email protected]>
|
| | | |
|
| | | |
|
| |\ \
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | | |
7822: Paperover a bug in cargo-workspace for publish RA r=lnicola a=edwin0cheng
r? @lnicola
See also https://github.com/pksunkara/cargo-workspaces/issues/39
Co-authored-by: Edwin Cheng <[email protected]>
|
| | |/ |
|
| |/ |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| |
|
|
| |
Handle parse error in rule parsing instead of match in mbe
|
| | |
|
| | |
|
| |
|
|
| |
It now stores text inline with tokens
|
| | |
|
| | |
|
| | |
|
