| Commit message (Collapse) | Author | Age | Files | Lines |
|---|
| ... | |
| |\
| |
| |
| |
| |
| |
| |
| | |
3218: Cut some deps r=matklad a=matklad
Co-authored-by: Aleksey Kladov <[email protected]>
|
| | | |
|
| | | |
|
| | | |
|
| |\ \
| |/
|/|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| | |
3026: ra_syntax: reshape SyntaxError for the sake of removing redundancy r=matklad a=Veetaha
Followup of #2911, also puts some crosses to the todo list of #223.
**AHTUNG!** A big part of the diff of this PR are test data files changes.
Simplified `SyntaxError` that was `SyntaxError { kind: { /* big enum */ }, location: Location }` to `SyntaxError(String, TextRange)`. I am not sure whether the tuple struct here is best fit, I am inclined to add names to the fields, because I already provide getters `SyntaxError::message()`, `SyntaxError::range()`.
I also removed `Location` altogether ...
This is currently WIP, because the following is not done:
- [ ] ~~Add tests to `test_data` dir for unescape errors *// I don't know where to put these errors in particular, because they are out of the scope of the lexer and parser. However, I have an idea in mind that we move all validators we have right now to parsing stage, but this is up to discussion...*~~ **[UPD]** I came to a conclusion that tree validation logic, which unescape errors are a part of, should be rethought of, we currently have no tests and no place to put tests for tree validations. So I'd like to extract potential redesign (maybe move of tree validation to ra_parser) and adding tests for this into a separate task.
Co-authored-by: Veetaha <[email protected]>
Co-authored-by: Veetaha <[email protected]>
|
| | | |
|
| | |
| |
| |
| | |
constructed from TextUnit
|
| | |
| |
| |
| | |
as per matklad
|
| | |
| |
| |
| | |
per matklad
|
| | | |
|
| | | |
|
| | | |
|
| | |
| |
| | |
Co-Authored-By: Aleksey Kladov <[email protected]>
|
| | |
| |
| | |
Co-Authored-By: Aleksey Kladov <[email protected]>
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| |/ |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| | |
|
| |
|
|
|
|
|
| |
It takes waaay to long to compile.
We should add quickcheck tests when we touch the relevant code next
time.
|
| |\
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| | |
3169: Show record field names in Enum completion r=flodiebold a=adamrk
Adresses https://github.com/rust-analyzer/rust-analyzer/issues/2947.
Previously the details shown when autocompleting an Enum variant would look like the variant was a tuple even if it was a record:
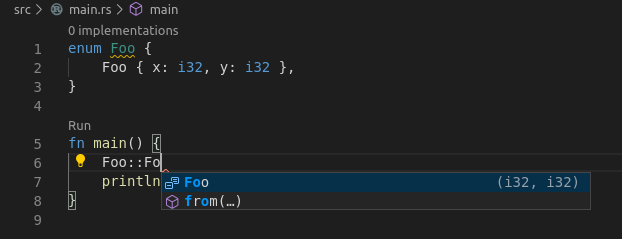
This change will show the names of the fields for a record and use curly braces instead of parentheses:
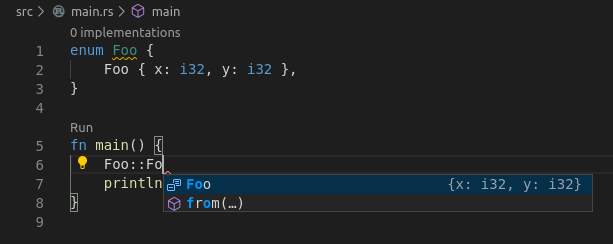
This required exposing the type `adt::StructKind` from `ra_hir` and adding a function
```
kind(self, db: &impl HirDatabase) -> StructKind
```
in the `impl` of `EnumVariant`.
There was also a previously existing function `is_unit(self, db: &impl HirDatabase) -> bool` for `EnumVariant` which I removed because it seemed redundant after adding `kind`.
Co-authored-by: adamrk <[email protected]>
|
| | | |
|
| | | |
|
| | | |
|
| | | |
|
| |\ \
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | | |
3099: Init implementation of structural search replace r=matklad a=mikhail-m1
next steps:
* ignore space and other minor difference
* add support to ra_cli
* call rust parser to check pattern
* documentation
original issue #2267
Co-authored-by: Mikhail Modin <[email protected]>
|
