| Commit message (Collapse) | Author | Age | Files | Lines |
|---|
| ... | |
| | | | | | | |
|
| | | | |/ /
| | |/| | |
|
| | | | | | |
|
| | | | | | |
|
| | | | | | | |
| | \ \ \ \ | |
| |\ \ \ \ \ \
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
8036: completions: provide relevance bonus for enum types, and suggest ref matches for fn and enum r=matklad a=JoshMcguigan
This PR makes several improvements to completions and completion sorting:
1. Provide exact match type relevance score bonus for enum variants
2. Suggest `&Foo` (ref_match) for enums if that is an exact type match
3. Suggest `&foo()` (ref_match) if `foo` returns a type which would be an exact match either with the reference or due to a `Deref` impl
### Before
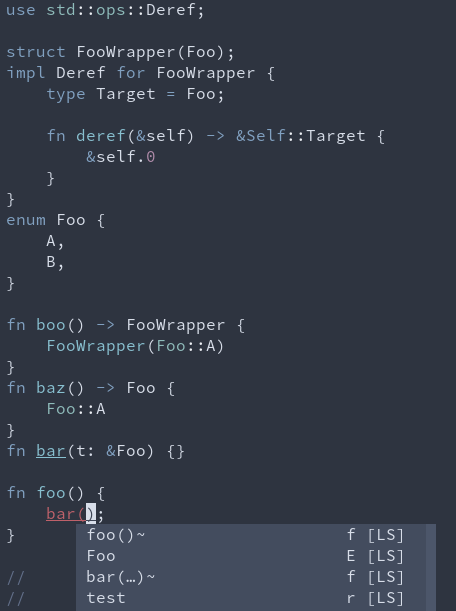
### After
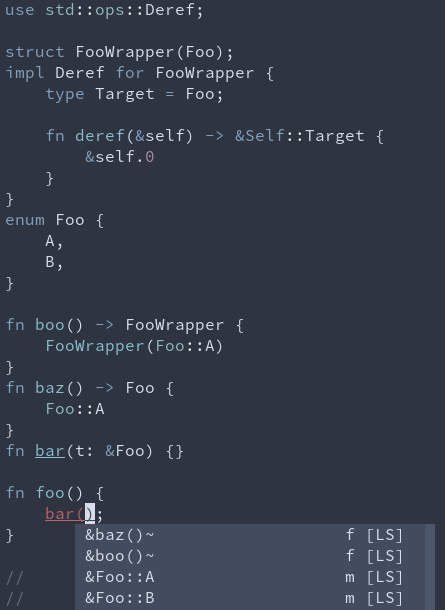
### Caveats
I think generic types will require some kind of fancier logic when testing for `exact_type_match`, so for now `Option`/`Result`/etc unfortunately still don't have great completions.
### Implementation
I implemented this in a way that I think makes it most likely for each completion type to be handled consistently. Just replace `CompletionItem::new` with `CompletionItem::new_with_type_info` and `exact_type_match`/`exact_name_match`/`ref_match` are all handled for you, in a way which is sure to be consistent across completion types.
This approach does introduce some coupling/plumbing that didn't exist before. Notice for example `set_is_local` on the builder, because `set_relevance` was removed from the builder to enforce that the relevance was built "properly" with `CompletionItem::new_with_type_info`. But I think there are benefits to this approach, like `CompletionRelevance` should probably consider deprecation status, and we already tell the builder about that, so in the (likely near term) future we can just pass that information along to `CompletionRelevance` when the user calls `set_deprecated` rather than the user having to manually set it in two places. This basically just hides `CompletionRelevance` from the individual completions, so they only worry about the `CompletionItem` interface. At the moment this seems like a cleaner approach to me, but I'm open to feedback here.
edit - I've reimplemented this in a simpler way, per feedback below.
8046: Prefer match to if let else r=matklad a=matklad
bors r+
🤖
Co-authored-by: Josh Mcguigan <[email protected]>
Co-authored-by: Aleksey Kladov <[email protected]>
|
| | | |_|_|_|/
| |/| | | | |
|
| |\ \ \ \ \ \
| |_|_|_|_|/
|/| | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
8040: 7709: Added the check for return type of len function. r=Veykril a=chetankhilosiya
Co-authored-by: Chetan Khilosiya <[email protected]>
|
| | | | | | | |
|
| | |/ / / / |
|
| |/ / / / |
|
| | | | |
| | | |
| | | |
| | | |
| | | | |
Doesn't help as much as I hoped, but it helps a bit and I also did some
refactorings that were necessary anyway.
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
7970: Fix incorrect diagnostics for failing built in macros r=jonas-schievink a=brandondong
**Reproduction:**
1. Use a built in macro in such a way that rust-analyzer fails to expand it. For example:
**lib.rs**
```
include!("<valid file but without a .rs extension so it is not indexed by rust-analyzer>");
```
2. rust-analyzer highlights the macro call and says the macro itself cannot be resolved even though include! is in the standard library (unresolved-macro-call diagnostic).
3. No macro-error diagnostic is raised.
**Root cause for incorrect unresolved-macro-call diagnostic:**
1. collector:collect_macro_call is able to resolve include! in legacy scope but the expansion fails. Therefore, it's pushed into unexpanded_macros to be retried with module scope.
2. include! fails at the resolution step in collector:resolve_macros now that it's using module scope. Therefore, it's retained in unexpanded_macros.
3. Finally, collector:finish tries resolving the remaining unexpanded macros but only with module scope. include! again fails at the resolution step so a diagnostic is created.
**Root cause for missing macro-error diagnostic:**
1. In collector:resolve_macros, directive.legacy is None since eager expansion failed in collector:collect_macro_call. The macro_call_as_call_id fails to resolve since we're retrying in module scope. Therefore, collect_macro_expansion is not called for the macro and no macro-error diagnostic is generated.
**Fix:**
- In collector:collect_macro_call, do not add failing built-in macros to the unexpanded_macros list and immediately raise the macro-error diagnostic. This is in contrast to lazy macros which are resolved in collector::resolve_macros and later expanded in collect_macro_expansion where a macro-error diagnostic may be raised.
Co-authored-by: Brandon <[email protected]>
Co-authored-by: brandondong <[email protected]>
|
| | | | | |
| | | | |
| | | | | |
Co-authored-by: Jonas Schievink <[email protected]>
|
| | | | | | |
|
| | | | | | |
|
| |\ \ \ \ \
| |_|/ / /
|/| | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
8038: Fix unification logic r=flodiebold a=flodiebold
Co-authored-by: Florian Diebold <[email protected]>
|
| | | | | | |
|
| |\ \ \ \ \
| |/ / / /
|/| | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
8028: Return multiple modules in `parent_module` feature r=matklad a=Veykril
Co-authored-by: Lukas Wirth <[email protected]>
|
| | | | | | |
|
| |\ \ \ \ \
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
8037: Assist is empty 7709 r=Veykril a=chetankhilosiya
Updated the implementation to get the function from implementation
Co-authored-by: Chetan Khilosiya <[email protected]>
|
| | | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
The get function from impl method is updated.
and now same method used to get len and is_empty function.
|
| | | |_|_|/
| |/| | |
| | | | |
| | | | |
| | | | | |
the assist will be shown when the len function is implemented.
is_empty internally uses len function.
|
| |\ \ \ \ \
| |/ / / /
|/| | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
8035: unqualfied_path completions aren't responsible for variant pattern completions r=Veykril a=Veykril
bors r+
Co-authored-by: Lukas Wirth <[email protected]>
|
| | | | | | |
|
| |\ \ \ \ \
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
7992: improved completion sorting for functions and methods r=JoshMcguigan a=JoshMcguigan
This PR improves completion sorting for functions and methods. Related to #7935.
### Before
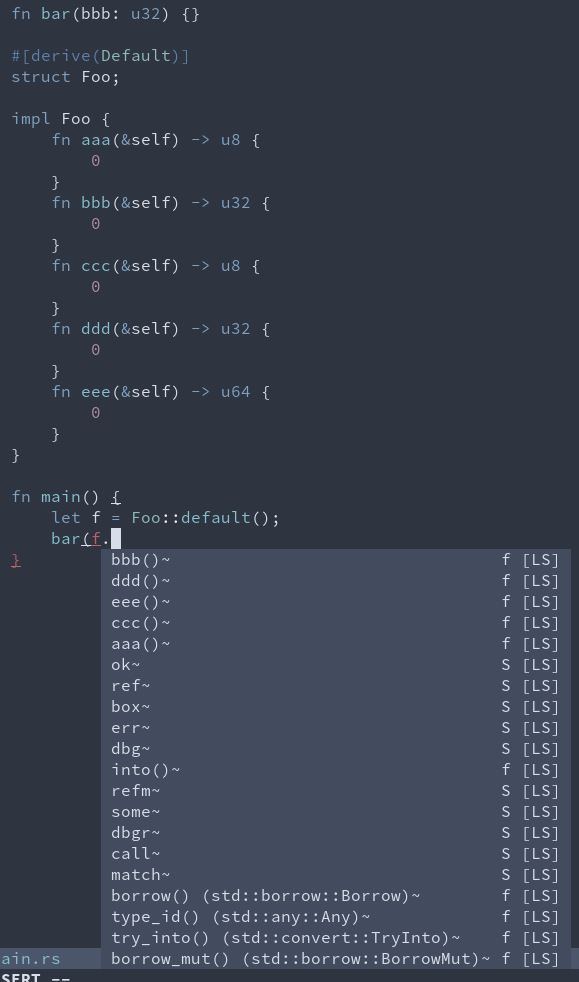
The methods are being sorted by `coc` by closeness in file.

### After
Notice `bbb()` on top (type + name match), followed by `ddd()` (type match).
Co-authored-by: Josh Mcguigan <[email protected]>
|
| | |/ / / / |
|
| |\ \ \ \ \
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
8033: Add test for proc-macro meta info retrieval r=edwin0cheng a=edwin0cheng
bors r+
Co-authored-by: Edwin Cheng <[email protected]>
|
| | |/ / / / |
|
| |/ / / / |
|
| |\ \ \ \
| |/ / /
|/| | |
| | | |
| | | |
| | | |
| | | |
| | | | |
8029: Enable thread-local coverage marks r=JoshMcguigan a=lnicola
Co-authored-by: Laurențiu Nicola <[email protected]>
|
| | | | | |
|
| | | | | |
|
| |\ \ \ \
| |/ / /
|/| | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | | |
8020: Power up goto_implementation r=matklad a=Veykril
by allowing it to be invoked on references of names, now showing all (trait)
implementations of the given type in all crates instead of just the defining
crate as well as including support for builtin types
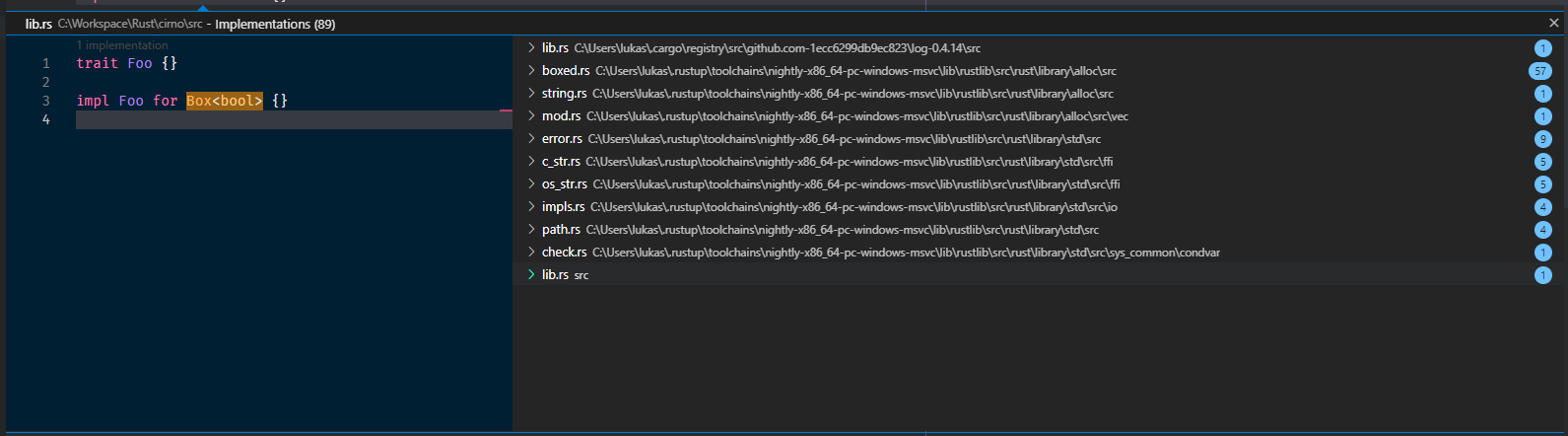
Example screenshot of `impl`s of Box in `log`, `alloc`, `std` and the current crate. Before you had to invoke it on the definition where it would only show the `impls` in `alloc`.
Co-authored-by: Lukas Wirth <[email protected]>
|
| | | | | |
|
| | | | | |
|
| | | | |
| | | |
| | | |
| | | |
| | | | |
by allowing it to be invoked on references of names, showing all (trait)
implementations of the given type in all crates including builtin types
|
| |\ \ \ \
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
8027: Completion context remove exact match method in favor of fields r=JoshMcguigan a=JoshMcguigan
This is a minor cleanup PR following #8008. It removes the `expected_name_and_type` method on completion context in favor of using the fields.
I thought this method was used in more places, or else it may have just made sense to make this change directly in #8008 :shrug:
Co-authored-by: Josh Mcguigan <[email protected]>
|
| | | | | |
| | | | |
| | | | |
| | | | | |
fields added in #8008
|
| |\ \ \ \ \
| |/ / / /
|/| | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
8015: Introduce Semantics::visit_file_defs r=matklad a=Veykril
See https://github.com/rust-analyzer/rust-analyzer/issues/3538#issuecomment-798920601
Co-authored-by: Lukas Wirth <[email protected]>
|
| | | | | | |
|
| | | | | | |
|
| |\ \ \ \ \
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
8008: Completion context expected type r=matklad a=JoshMcguigan
Currently there are two ways completions use to determine the expected type. There is the `expected_type` field on the `CompletionContext`, as well as the `expected_name_and_type` method on the `RenderContext`. These two things returned slightly different results, and their results were only valid if you had pre-checked some (undocumented) invariants. A simple combination of the two approaches doesn't work because they are both too willing to go far up the syntax tree to find something that fits what they are looking for.
This PR makes the following changes:
1. Updates the algorithm that sets `expected_type` on `CompletionContext`
2. Adds `expected_name` field to `CompletionContext`
3. Re-writes the `expected_name_and_type` method to simply return the underlying fields from `CompletionContext` (I'd like to save actually removing this method for a follow up PR just to keep the scope of the changes down)
4. Adds unit tests for the `expected_type`/`expected_name` fields
All the existing unit tests still pass (unmodified), but this new algorithm certainly has some gaps (although I believe all the `FIXME` introduced in this PR are also flaws in the current code). I wanted to stop here and get some feedback though - is this approach fundamentally sound?
Co-authored-by: Josh Mcguigan <[email protected]>
|
| | | | | | | |
|
| |\ \ \ \ \ \
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
8018: Make Ty wrap TyKind in an Arc r=flodiebold a=flodiebold
... to further move towards Chalk.
This is a bit of a slowdown (218ginstr vs 213ginstr for inference on RA), even though it allows us to unwrap the Substs in `TyKind::Ref` etc..
Co-authored-by: Florian Diebold <[email protected]>
|
| | | | | | | | |
|
| | | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
... like it will be in Chalk. We still keep `interned_mut` and
`into_inner` methods that will probably not exist with Chalk.
This worsens performance slightly (5ginstr inference on RA), but doesn't
include other simplifications we can do yet.
|
| | |/ / / / /
|/| | | | | |
|
| | |/ / / /
|/| | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | | |
What happens here is that we lower `: ` to a missing expression, and
then correctly record that the corresponding field expression resolves
to a specific field. Where we fail is in the mapping of syntax to this
missing expression. Doing it via `ast_field.expr()` fails, as that
expression is `None`. Instead, we go in the opposite direcition and ask
each lowered field about its source.
This works, but has wrong complexity `O(N)` and, really, the
implementation is just too complex. We need some better management of
data here.
|
| | | | | | | |
| | \ \ \ \ | |
| |\ \ \ \ \ \
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | | |
8021: Enable searching for builtin types r=matklad a=Veykril
Not too sure how useful this is for reference search overall, but for completeness sake it should be there
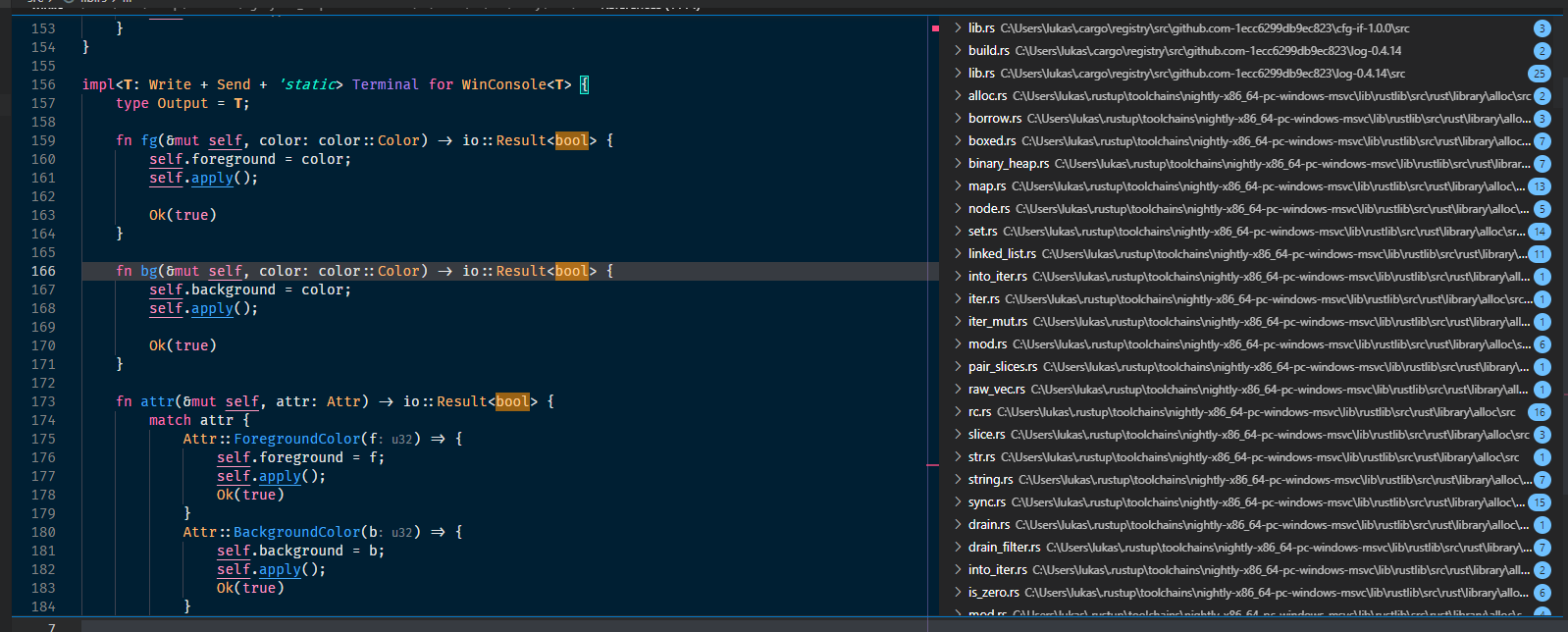
Also enables document highlighting for them.
8022: some clippy::performance fixes r=matklad a=matthiaskrgr
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unnecessary resizing
Co-authored-by: Lukas Wirth <[email protected]>
Co-authored-by: Matthias Krüger <[email protected]>
|
| | | | |/ / /
| | |/| | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | | |
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
|
