
diff options
| author | bors[bot] <bors[bot]@users.noreply.github.com> | 2019-03-20 14:48:25 +0000 |
|---|---|---|
| committer | bors[bot] <bors[bot]@users.noreply.github.com> | 2019-03-20 14:48:25 +0000 |
| commit | 90ff3ba64133c1bcae9d49709c4dd704ae59b1ee (patch) | |
| tree | 7bc6798bb03af8148effab8f6a8a304d05d171bd /docs/dev | |
| parent | 69ee5c9c5ef212f7911028c9ddf581559e6565c3 (diff) | |
| parent | 290237d2eb472522191721397d0c4db905cdc565 (diff) | |
Merge #1000
1000: Clean up some documentation debt r=Xanewok a=matklad
Co-authored-by: Aleksey Kladov <[email protected]>
Co-authored-by: bjorn3 <[email protected]>
Diffstat (limited to 'docs/dev')
| -rw-r--r-- | docs/dev/README.md | 124 | ||||
| -rw-r--r-- | docs/dev/architecture.md | 199 | ||||
| -rw-r--r-- | docs/dev/debugging.md | 62 | ||||
| -rw-r--r-- | docs/dev/guide.md | 575 | ||||
| -rw-r--r-- | docs/dev/lsp-features.md | 74 |
5 files changed, 1034 insertions, 0 deletions
diff --git a/docs/dev/README.md b/docs/dev/README.md new file mode 100644 index 000000000..ac7f4fd71 --- /dev/null +++ b/docs/dev/README.md | |||
| @@ -0,0 +1,124 @@ | |||
| 1 | # Contributing Quick Start | ||
| 2 | |||
| 3 | Rust Analyzer is just a usual rust project, which is organized as a Cargo | ||
| 4 | workspace, builds on stable and doesn't depend on C libraries. So, just | ||
| 5 | |||
| 6 | ``` | ||
| 7 | $ cargo test | ||
| 8 | ``` | ||
| 9 | |||
| 10 | should be enough to get you started! | ||
| 11 | |||
| 12 | To learn more about how rust-analyzer works, see | ||
| 13 | [./architecture.md](./architecture.md) document. | ||
| 14 | |||
| 15 | Various organizational and process issues are discussed here. | ||
| 16 | |||
| 17 | # Getting in Touch | ||
| 18 | |||
| 19 | Rust Analyzer is a part of [RLS-2.0 working | ||
| 20 | group](https://github.com/rust-lang/compiler-team/tree/6a769c13656c0a6959ebc09e7b1f7c09b86fb9c0/working-groups/rls-2.0). | ||
| 21 | Discussion happens in this Zulip stream: | ||
| 22 | |||
| 23 | https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Fwg-rls-2.2E0 | ||
| 24 | |||
| 25 | # Issue Labels | ||
| 26 | |||
| 27 | * [good-first-issue](https://github.com/rust-analyzer/rust-analyzer/labels/good%20first%20issue) | ||
| 28 | are good issues to get into the project. | ||
| 29 | * [E-mentor](https://github.com/rust-analyzer/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-mentor) | ||
| 30 | issues have links to the code in question and tests. | ||
| 31 | * [E-easy](https://github.com/rust-analyzer/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-easy), | ||
| 32 | [E-medium](https://github.com/rust-analyzer/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-medium), | ||
| 33 | [E-hard](https://github.com/rust-analyzer/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-hard), | ||
| 34 | labels are *estimates* for how hard would be to write a fix. | ||
| 35 | * [E-fun](https://github.com/rust-analyzer/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-fun) | ||
| 36 | is for cool, but probably hard stuff. | ||
| 37 | |||
| 38 | # CI | ||
| 39 | |||
| 40 | We use Travis for CI. Most of the things, including formatting, are checked by | ||
| 41 | `cargo test` so, if `cargo test` passes locally, that's a good sign that CI will | ||
| 42 | be green as well. We use bors-ng to enforce the [not rocket | ||
| 43 | science](https://graydon2.dreamwidth.org/1597.html) rule. | ||
| 44 | |||
| 45 | You can run `cargo format-hook` to install git-hook to run rustfmt on commit. | ||
| 46 | |||
| 47 | # Code organization | ||
| 48 | |||
| 49 | All Rust code lives in the `crates` top-level directory, and is organized as a | ||
| 50 | single Cargo workspace. The `editors` top-level directory contains code for | ||
| 51 | integrating with editors. Currently, it contains plugins for VS Code (in | ||
| 52 | typescript) and Emacs (in elisp). The `docs` top-level directory contains both | ||
| 53 | developer and user documentation. | ||
| 54 | |||
| 55 | We have some automation infra in Rust in the `crates/tool` package. It contains | ||
| 56 | stuff like formatting checking, code generation and powers `cargo install-code`. | ||
| 57 | The latter syntax is achieved with the help of cargo aliases (see `.cargo` | ||
| 58 | directory). | ||
| 59 | |||
| 60 | # Launching rust-analyzer | ||
| 61 | |||
| 62 | Debugging language server can be tricky: LSP is rather chatty, so driving it | ||
| 63 | from the command line is not really feasible, driving it via VS Code requires | ||
| 64 | interacting with two processes. | ||
| 65 | |||
| 66 | For this reason, the best way to see how rust-analyzer works is to find a | ||
| 67 | relevant test and execute it (VS Code includes an action for running a single | ||
| 68 | test). | ||
| 69 | |||
| 70 | However, launching a VS Code instance with locally build language server is | ||
| 71 | possible. There's even a VS Code task for this, so just <kbd>F5</kbd> should | ||
| 72 | work (thanks, [@andrew-w-ross](https://github.com/andrew-w-ross)!). | ||
| 73 | |||
| 74 | I often just install development version with `cargo jinstall-lsp` and | ||
| 75 | restart the host VS Code. | ||
| 76 | |||
| 77 | See [./debugging.md](./debugging.md) for how to attach to rust-analyzer with | ||
| 78 | debugger, and don't forget that rust-analyzer has useful `pd` snippet and `dbg` | ||
| 79 | postfix completion for printf debugging :-) | ||
| 80 | |||
| 81 | # Working With VS Code Extension | ||
| 82 | |||
| 83 | To work on the VS Code extension, launch code inside `editors/code` and use `F5` | ||
| 84 | to launch/debug. To automatically apply formatter and linter suggestions, use | ||
| 85 | `npm run fix`. | ||
| 86 | |||
| 87 | # Logging | ||
| 88 | |||
| 89 | Logging is done by both rust-analyzer and VS Code, so it might be tricky to | ||
| 90 | figure out where logs go. | ||
| 91 | |||
| 92 | Inside rust-analyzer, we use the standard `log` crate for logging, and | ||
| 93 | `flexi_logger` for logging frotend. By default, log goes to stderr (the same as | ||
| 94 | with `env_logger`), but the stderr itself is processed by VS Code. To mirror | ||
| 95 | logs to a `./log` directory, set `RA_INTERNAL_MODE=1` environmental variable. | ||
| 96 | |||
| 97 | To see stderr in the running VS Code instance, go to the "Output" tab of the | ||
| 98 | panel and select `rust-analyzer`. This shows `eprintln!` as well. Note that | ||
| 99 | `stdout` is used for the actual protocol, so `println!` will break things. | ||
| 100 | |||
| 101 | To log all communication between the server and the client, there are two choices: | ||
| 102 | |||
| 103 | * you can log on the server side, by running something like | ||
| 104 | ``` | ||
| 105 | env RUST_LOG=gen_lsp_server=trace code . | ||
| 106 | ``` | ||
| 107 | |||
| 108 | * you can log on the client side, by enabling `"rust-analyzer.trace.server": | ||
| 109 | "verbose"` workspace setting. These logs are shown in a separate tab in the | ||
| 110 | output and could be used with LSP inspector. Kudos to | ||
| 111 | [@DJMcNab](https://github.com/DJMcNab) for setting this awesome infra up! | ||
| 112 | |||
| 113 | |||
| 114 | There's also two VS Code commands which might be of interest: | ||
| 115 | |||
| 116 | * `Rust Analyzer: Status` shows some memory-usage statistics. To take full | ||
| 117 | advantage of it, you need to compile rust-analyzer with jemalloc support: | ||
| 118 | ``` | ||
| 119 | $ cargo install --path crates/ra_lsp_server --force --features jemalloc | ||
| 120 | ``` | ||
| 121 | |||
| 122 | There's an alias for this: `cargo jinstall-lsp`. | ||
| 123 | |||
| 124 | * `Rust Analyzer: Syntax Tree` shows syntax tree of the current file/selection. | ||
diff --git a/docs/dev/architecture.md b/docs/dev/architecture.md new file mode 100644 index 000000000..f990d5bf0 --- /dev/null +++ b/docs/dev/architecture.md | |||
| @@ -0,0 +1,199 @@ | |||
| 1 | # Architecture | ||
| 2 | |||
| 3 | This document describes the high-level architecture of rust-analyzer. | ||
| 4 | If you want to familiarize yourself with the code base, you are just | ||
| 5 | in the right place! | ||
| 6 | |||
| 7 | See also the [guide](./guide.md), which walks through a particular snapshot of | ||
| 8 | rust-analyzer code base. | ||
| 9 | |||
| 10 | Yet another resource is this playlist with videos about various parts of the | ||
| 11 | analyzer: | ||
| 12 | |||
| 13 | https://www.youtube.com/playlist?list=PL85XCvVPmGQho7MZkdW-wtPtuJcFpzycE | ||
| 14 | |||
| 15 | ## The Big Picture | ||
| 16 | |||
| 17 | 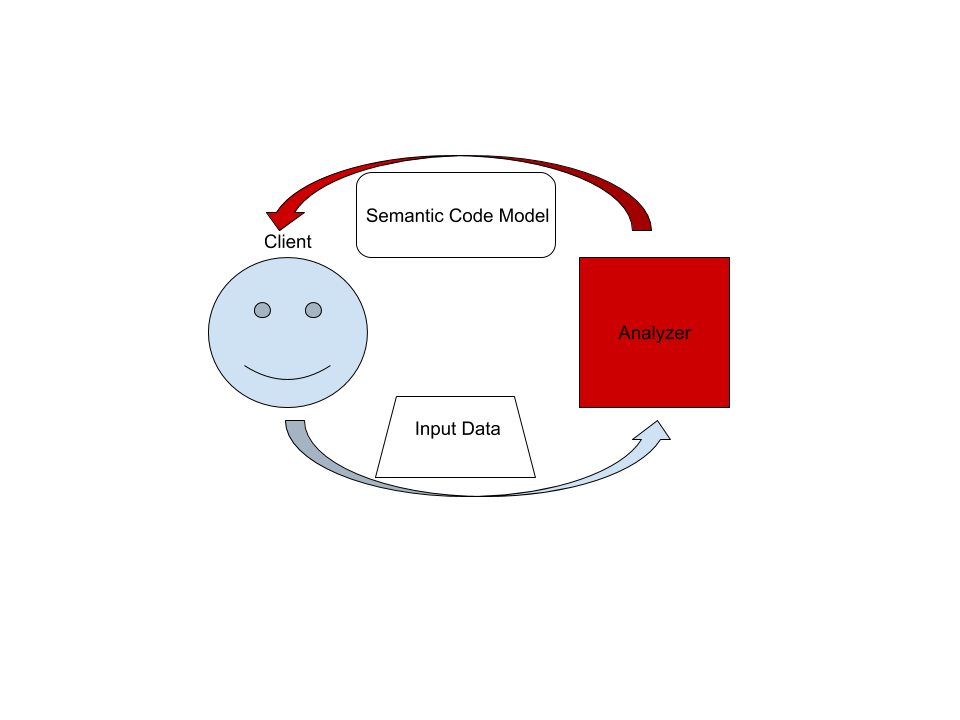 | ||
| 18 | |||
| 19 | On the highest level, rust-analyzer is a thing which accepts input source code | ||
| 20 | from the client and produces a structured semantic model of the code. | ||
| 21 | |||
| 22 | More specifically, input data consists of a set of test files (`(PathBuf, | ||
| 23 | String)` pairs) and information about project structure, captured in the so called | ||
| 24 | `CrateGraph`. The crate graph specifies which files are crate roots, which cfg | ||
| 25 | flags are specified for each crate (TODO: actually implement this) and what | ||
| 26 | dependencies exist between the crates. The analyzer keeps all this input data in | ||
| 27 | memory and never does any IO. Because the input data is source code, which | ||
| 28 | typically measures in tens of megabytes at most, keeping all input data in | ||
| 29 | memory is OK. | ||
| 30 | |||
| 31 | A "structured semantic model" is basically an object-oriented representation of | ||
| 32 | modules, functions and types which appear in the source code. This representation | ||
| 33 | is fully "resolved": all expressions have types, all references are bound to | ||
| 34 | declarations, etc. | ||
| 35 | |||
| 36 | The client can submit a small delta of input data (typically, a change to a | ||
| 37 | single file) and get a fresh code model which accounts for changes. | ||
| 38 | |||
| 39 | The underlying engine makes sure that model is computed lazily (on-demand) and | ||
| 40 | can be quickly updated for small modifications. | ||
| 41 | |||
| 42 | |||
| 43 | ## Code generation | ||
| 44 | |||
| 45 | Some of the components of this repository are generated through automatic | ||
| 46 | processes. These are outlined below: | ||
| 47 | |||
| 48 | - `gen-syntax`: The kinds of tokens that are reused in several places, so a generator | ||
| 49 | is used. We use tera templates to generate the files listed below, based on | ||
| 50 | the grammar described in [grammar.ron]: | ||
| 51 | - [ast/generated.rs][ast generated] in `ra_syntax` based on | ||
| 52 | [ast/generated.tera.rs][ast source] | ||
| 53 | - [syntax_kinds/generated.rs][syntax_kinds generated] in `ra_syntax` based on | ||
| 54 | [syntax_kinds/generated.tera.rs][syntax_kinds source] | ||
| 55 | |||
| 56 | [tera]: https://tera.netlify.com/ | ||
| 57 | [grammar.ron]: ./crates/ra_syntax/src/grammar.ron | ||
| 58 | [ast generated]: ./crates/ra_syntax/src/ast/generated.rs | ||
| 59 | [ast source]: ./crates/ra_syntax/src/ast/generated.rs.tera | ||
| 60 | [syntax_kinds generated]: ./crates/ra_syntax/src/syntax_kinds/generated.rs | ||
| 61 | [syntax_kinds source]: ./crates/ra_syntax/src/syntax_kinds/generated.rs.tera | ||
| 62 | |||
| 63 | |||
| 64 | ## Code Walk-Through | ||
| 65 | |||
| 66 | ### `crates/ra_syntax`, `crates/ra_parser` | ||
| 67 | |||
| 68 | Rust syntax tree structure and parser. See | ||
| 69 | [RFC](https://github.com/rust-lang/rfcs/pull/2256) for some design notes. | ||
| 70 | |||
| 71 | - [rowan](https://github.com/rust-analyzer/rowan) library is used for constructing syntax trees. | ||
| 72 | - `grammar` module is the actual parser. It is a hand-written recursive descent parser, which | ||
| 73 | produces a sequence of events like "start node X", "finish not Y". It works similarly to [kotlin's parser](https://github.com/JetBrains/kotlin/blob/4d951de616b20feca92f3e9cc9679b2de9e65195/compiler/frontend/src/org/jetbrains/kotlin/parsing/KotlinParsing.java), | ||
| 74 | which is a good source of inspiration for dealing with syntax errors and incomplete input. Original [libsyntax parser](https://github.com/rust-lang/rust/blob/6b99adeb11313197f409b4f7c4083c2ceca8a4fe/src/libsyntax/parse/parser.rs) | ||
| 75 | is what we use for the definition of the Rust language. | ||
| 76 | - `parser_api/parser_impl` bridges the tree-agnostic parser from `grammar` with `rowan` trees. | ||
| 77 | This is the thing that turns a flat list of events into a tree (see `EventProcessor`) | ||
| 78 | - `ast` provides a type safe API on top of the raw `rowan` tree. | ||
| 79 | - `grammar.ron` RON description of the grammar, which is used to | ||
| 80 | generate `syntax_kinds` and `ast` modules, using `cargo gen-syntax` command. | ||
| 81 | - `algo`: generic tree algorithms, including `walk` for O(1) stack | ||
| 82 | space tree traversal (this is cool) and `visit` for type-driven | ||
| 83 | visiting the nodes (this is double plus cool, if you understand how | ||
| 84 | `Visitor` works, you understand the design of syntax trees). | ||
| 85 | |||
| 86 | Tests for ra_syntax are mostly data-driven: `tests/data/parser` contains a bunch of `.rs` | ||
| 87 | (test vectors) and `.txt` files with corresponding syntax trees. During testing, we check | ||
| 88 | `.rs` against `.txt`. If the `.txt` file is missing, it is created (this is how you update | ||
| 89 | tests). Additionally, running `cargo gen-tests` will walk the grammar module and collect | ||
| 90 | all `//test test_name` comments into files inside `tests/data` directory. | ||
| 91 | |||
| 92 | See [#93](https://github.com/rust-analyzer/rust-analyzer/pull/93) for an example PR which | ||
| 93 | fixes a bug in the grammar. | ||
| 94 | |||
| 95 | ### `crates/ra_db` | ||
| 96 | |||
| 97 | We use the [salsa](https://github.com/salsa-rs/salsa) crate for incremental and | ||
| 98 | on-demand computation. Roughly, you can think of salsa as a key-value store, but | ||
| 99 | it also can compute derived values using specified functions. The `ra_db` crate | ||
| 100 | provides basic infrastructure for interacting with salsa. Crucially, it | ||
| 101 | defines most of the "input" queries: facts supplied by the client of the | ||
| 102 | analyzer. Reading the docs of the `ra_db::input` module should be useful: | ||
| 103 | everything else is strictly derived from those inputs. | ||
| 104 | |||
| 105 | ### `crates/ra_hir` | ||
| 106 | |||
| 107 | HIR provides high-level "object oriented" access to Rust code. | ||
| 108 | |||
| 109 | The principal difference between HIR and syntax trees is that HIR is bound to a | ||
| 110 | particular crate instance. That is, it has cfg flags and features applied (in | ||
| 111 | theory, in practice this is to be implemented). So, the relation between | ||
| 112 | syntax and HIR is many-to-one. The `source_binder` module is responsible for | ||
| 113 | guessing a HIR for a particular source position. | ||
| 114 | |||
| 115 | Underneath, HIR works on top of salsa, using a `HirDatabase` trait. | ||
| 116 | |||
| 117 | ### `crates/ra_ide_api` | ||
| 118 | |||
| 119 | A stateful library for analyzing many Rust files as they change. `AnalysisHost` | ||
| 120 | is a mutable entity (clojure's atom) which holds the current state, incorporates | ||
| 121 | changes and hands out `Analysis` --- an immutable and consistent snapshot of | ||
| 122 | the world state at a point in time, which actually powers analysis. | ||
| 123 | |||
| 124 | One interesting aspect of analysis is its support for cancellation. When a | ||
| 125 | change is applied to `AnalysisHost`, first all currently active snapshots are | ||
| 126 | canceled. Only after all snapshots are dropped the change actually affects the | ||
| 127 | database. | ||
| 128 | |||
| 129 | APIs in this crate are IDE centric: they take text offsets as input and produce | ||
| 130 | offsets and strings as output. This works on top of rich code model powered by | ||
| 131 | `hir`. | ||
| 132 | |||
| 133 | ### `crates/ra_ide_api_light` | ||
| 134 | |||
| 135 | All IDE features which can be implemented if you only have access to a single | ||
| 136 | file. `ra_ide_api_light` could be used to enhance editing of Rust code without | ||
| 137 | the need to fiddle with build-systems, file synchronization and such. | ||
| 138 | |||
| 139 | In a sense, `ra_ide_api_light` is just a bunch of pure functions which take a | ||
| 140 | syntax tree as input. | ||
| 141 | |||
| 142 | The tests for `ra_ide_api_light` are `#[cfg(test)] mod tests` unit-tests spread | ||
| 143 | throughout its modules. | ||
| 144 | |||
| 145 | |||
| 146 | ### `crates/ra_lsp_server` | ||
| 147 | |||
| 148 | An LSP implementation which wraps `ra_ide_api` into a langauge server protocol. | ||
| 149 | |||
| 150 | ### `ra_vfs` | ||
| 151 | |||
| 152 | Although `hir` and `ra_ide_api` don't do any IO, we need to be able to read | ||
| 153 | files from disk at the end of the day. This is what `ra_vfs` does. It also | ||
| 154 | manages overlays: "dirty" files in the editor, whose "true" contents is | ||
| 155 | different from data on disk. This is more or less the single really | ||
| 156 | platform-dependent component, so it lives in a separate repository and has an | ||
| 157 | extensive cross-platform CI testing. | ||
| 158 | |||
| 159 | ### `crates/gen_lsp_server` | ||
| 160 | |||
| 161 | A language server scaffold, exposing a synchronous crossbeam-channel based API. | ||
| 162 | This crate handles protocol handshaking and parsing messages, while you | ||
| 163 | control the message dispatch loop yourself. | ||
| 164 | |||
| 165 | Run with `RUST_LOG=sync_lsp_server=debug` to see all the messages. | ||
| 166 | |||
| 167 | ### `crates/ra_cli` | ||
| 168 | |||
| 169 | A CLI interface to rust-analyzer. | ||
| 170 | |||
| 171 | |||
| 172 | ## Testing Infrastructure | ||
| 173 | |||
| 174 | Rust Analyzer has three interesting [systems | ||
| 175 | boundaries](https://www.tedinski.com/2018/04/10/making-tests-a-positive-influence-on-design.html) | ||
| 176 | to concentrate tests on. | ||
| 177 | |||
| 178 | The outermost boundary is the `ra_lsp_server` crate, which defines an LSP | ||
| 179 | interface in terms of stdio. We do integration testing of this component, by | ||
| 180 | feeding it with a stream of LSP requests and checking responses. These tests are | ||
| 181 | known as "heavy", because they interact with Cargo and read real files from | ||
| 182 | disk. For this reason, we try to avoid writing too many tests on this boundary: | ||
| 183 | in a statically typed language, it's hard to make an error in the protocol | ||
| 184 | itself if messages are themselves typed. | ||
| 185 | |||
| 186 | The middle, and most important, boundary is `ra_ide_api`. Unlike | ||
| 187 | `ra_lsp_server`, which exposes API, `ide_api` uses Rust API and is intended to | ||
| 188 | use by various tools. Typical test creates an `AnalysisHost`, calls some | ||
| 189 | `Analysis` functions and compares the results against expectation. | ||
| 190 | |||
| 191 | The innermost and most elaborate boundary is `hir`. It has a much richer | ||
| 192 | vocabulary of types than `ide_api`, but the basic testing setup is the same: we | ||
| 193 | create a database, run some queries, assert result. | ||
| 194 | |||
| 195 | For comparisons, we use [insta](https://github.com/mitsuhiko/insta/) library for | ||
| 196 | snapshot testing. | ||
| 197 | |||
| 198 | To test various analysis corner cases and avoid forgetting about old tests, we | ||
| 199 | use so-called marks. See the `marks` module in the `test_utils` crate for more. | ||
diff --git a/docs/dev/debugging.md b/docs/dev/debugging.md new file mode 100644 index 000000000..f868e6998 --- /dev/null +++ b/docs/dev/debugging.md | |||
| @@ -0,0 +1,62 @@ | |||
| 1 | # Debugging vs Code plugin and the Language Server | ||
| 2 | |||
| 3 | Install [LLDB](https://lldb.llvm.org/) and the [LLDB Extension](https://marketplace.visualstudio.com/items?itemName=vadimcn.vscode-lldb). | ||
| 4 | |||
| 5 | Checkout rust rust-analyzer and open it in vscode. | ||
| 6 | |||
| 7 | ``` | ||
| 8 | $ git clone https://github.com/rust-analyzer/rust-analyzer.git --depth 1 | ||
| 9 | $ cd rust-analyzer | ||
| 10 | $ code . | ||
| 11 | ``` | ||
| 12 | |||
| 13 | - To attach to the `lsp server` in linux you'll have to run: | ||
| 14 | |||
| 15 | `echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope` | ||
| 16 | |||
| 17 | This enables ptrace on non forked processes | ||
| 18 | |||
| 19 | - Ensure the dependencies for the extension are installed, run the `npm: install - editors/code` task in vscode. | ||
| 20 | |||
| 21 | - Launch the `Debug Extension`, this will build the extension and the `lsp server`. | ||
| 22 | |||
| 23 | - A new instance of vscode with `[Extension Development Host]` in the title. | ||
| 24 | |||
| 25 | Don't worry about disabling `rls` all other extensions will be disabled but this one. | ||
| 26 | |||
| 27 | - In the new vscode instance open a rust project, and navigate to a rust file | ||
| 28 | |||
| 29 | - In the original vscode start an additional debug session (the three periods in the launch) and select `Debug Lsp Server`. | ||
| 30 | |||
| 31 | - A list of running processes should appear select the `ra_lsp_server` from this repo. | ||
| 32 | |||
| 33 | - Navigate to `crates/ra_lsp_server/src/main_loop.rs` and add a breakpoint to the `on_task` function. | ||
| 34 | |||
| 35 | - Go back to the `[Extension Development Host]` instance and hover over a rust variable and your breakpoint should hit. | ||
| 36 | |||
| 37 | ## Demo | ||
| 38 | |||
| 39 | 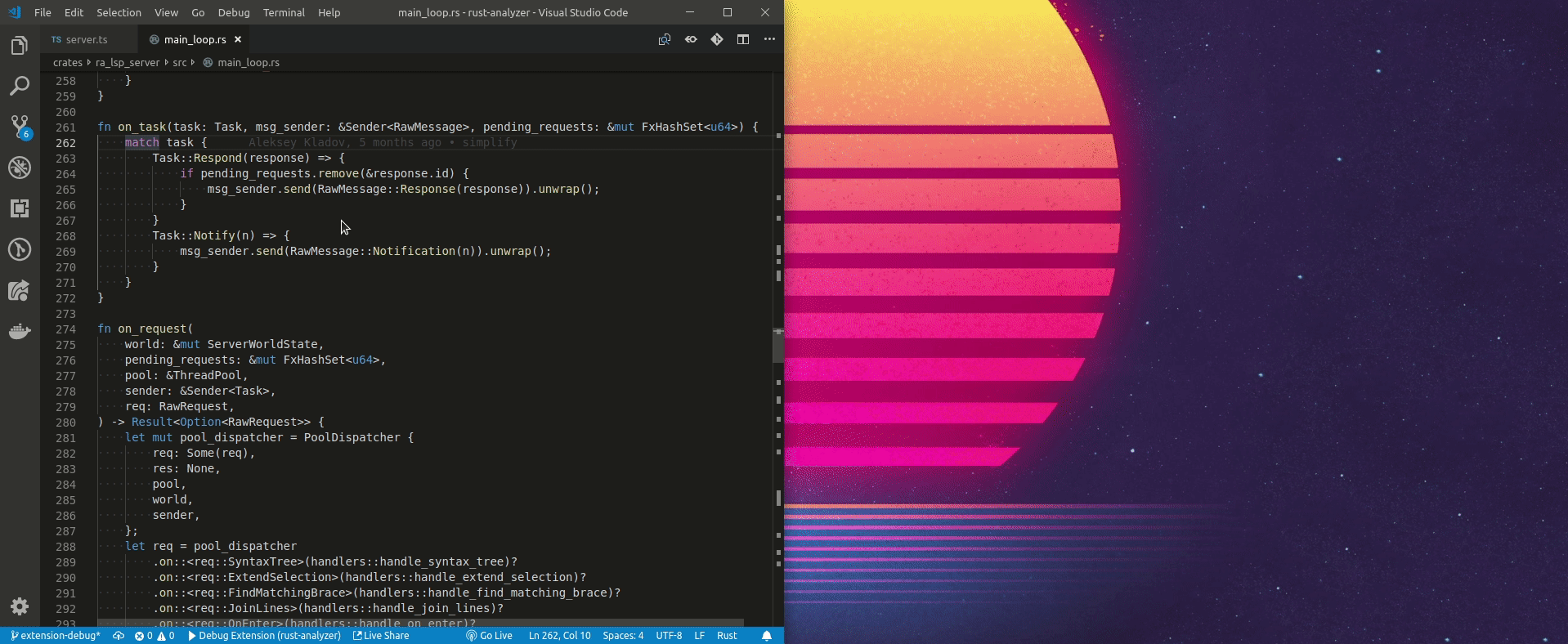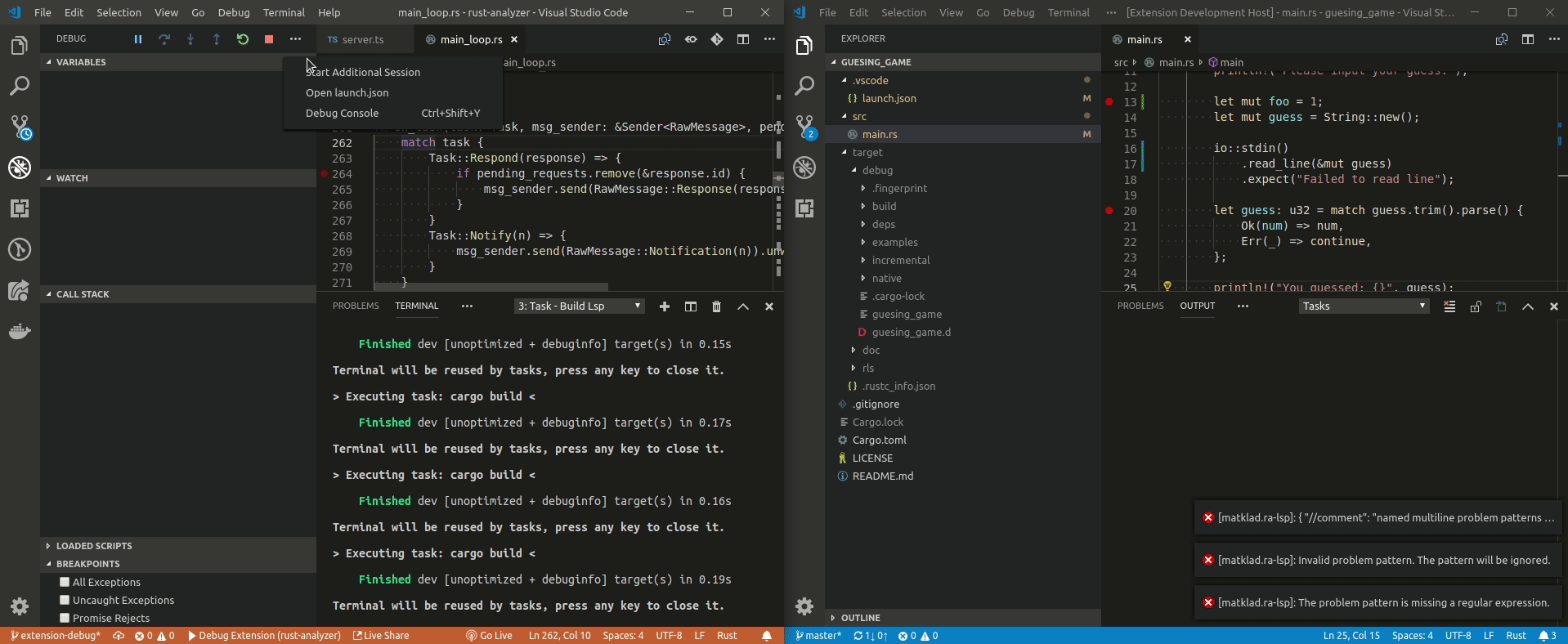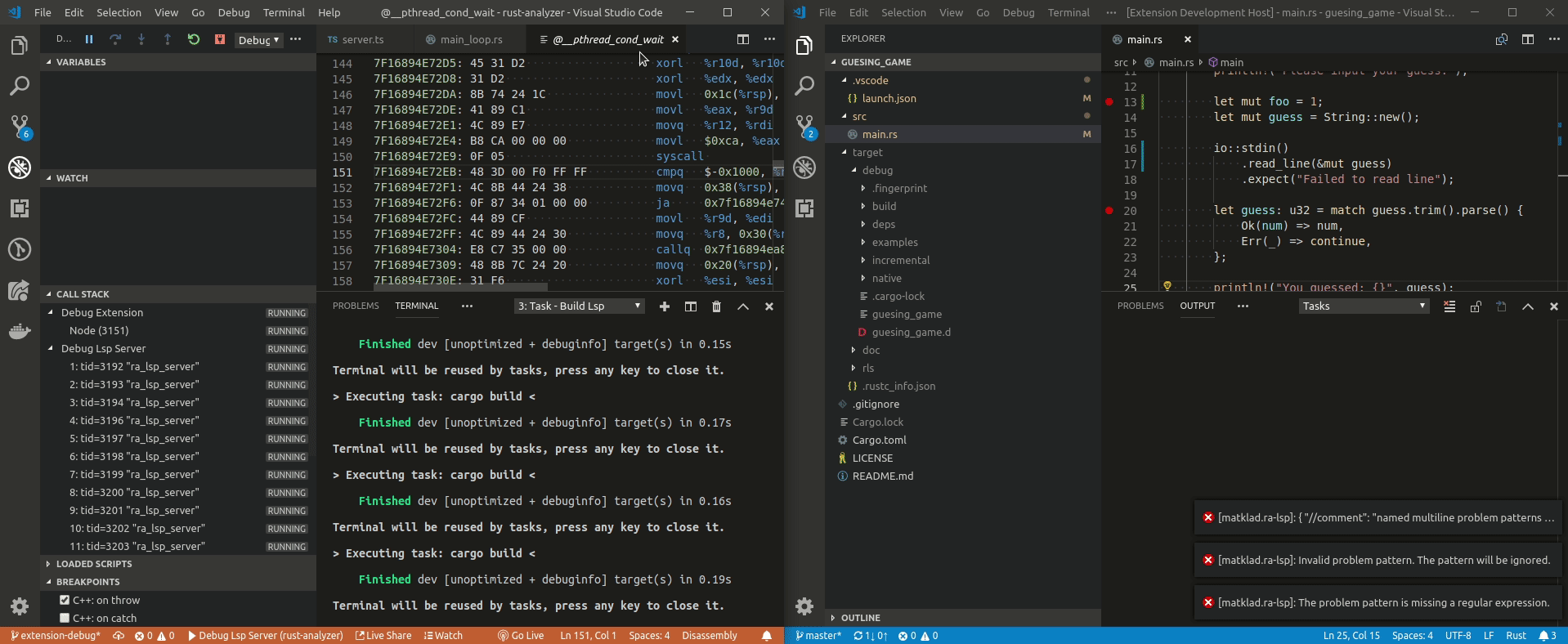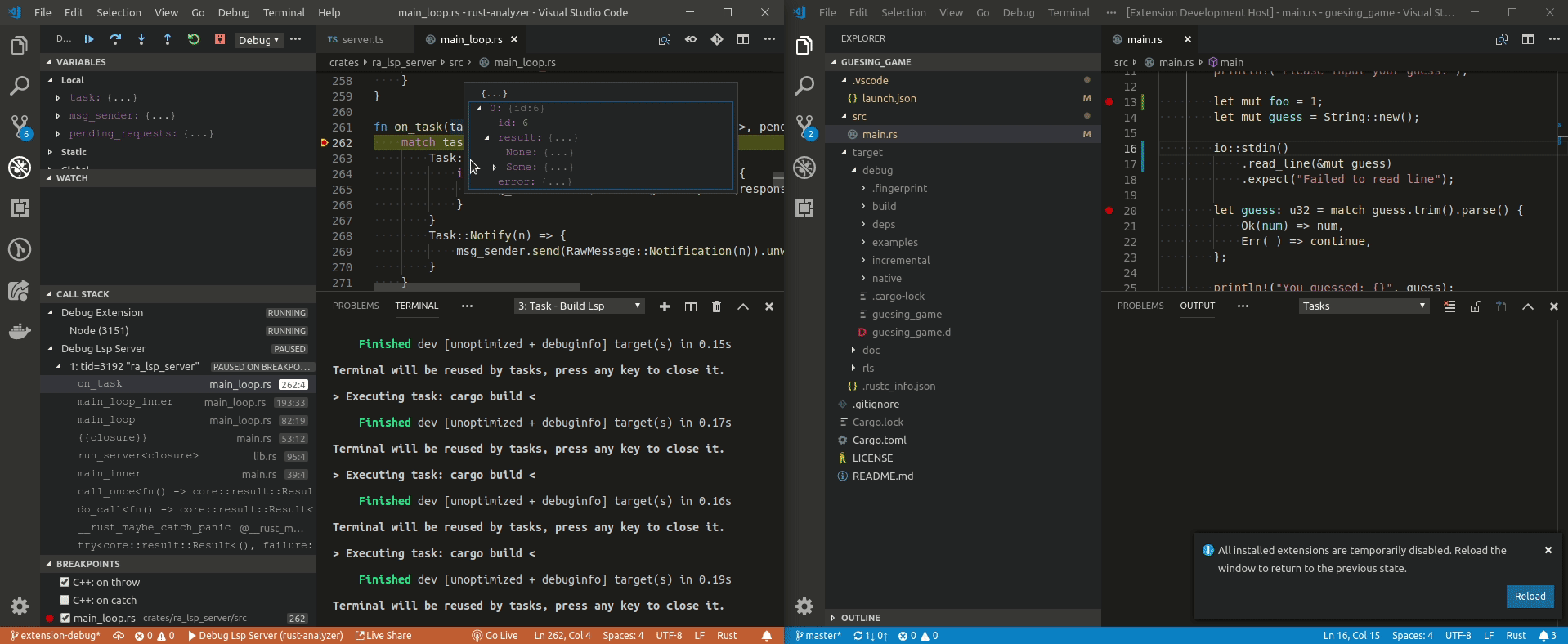 | ||
| 40 | |||
| 41 | ## Troubleshooting | ||
| 42 | |||
| 43 | ### Can't find the `ra_lsp_server` process | ||
| 44 | |||
| 45 | It could be a case of just jumping the gun. | ||
| 46 | |||
| 47 | The `ra_lsp_server` is only started once the `onLanguage:rust` activation. | ||
| 48 | |||
| 49 | Make sure you open a rust file in the `[Extension Development Host]` and try again. | ||
| 50 | |||
| 51 | ### Can't connect to `ra_lsp_server` | ||
| 52 | |||
| 53 | Make sure you have run `echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope`. | ||
| 54 | |||
| 55 | By default this should reset back to 1 everytime you log in. | ||
| 56 | |||
| 57 | ### Breakpoints are never being hit | ||
| 58 | |||
| 59 | Check your version of `lldb` if it's version 6 and lower use the `classic` adapter type. | ||
| 60 | It's `lldb.adapterType` in settings file. | ||
| 61 | |||
| 62 | If you're running `lldb` version 7 change the lldb adapter type to `bundled` or `native`. | ||
diff --git a/docs/dev/guide.md b/docs/dev/guide.md new file mode 100644 index 000000000..abbe4c154 --- /dev/null +++ b/docs/dev/guide.md | |||
| @@ -0,0 +1,575 @@ | |||
| 1 | # Guide to rust-analyzer | ||
| 2 | |||
| 3 | ## About the guide | ||
| 4 | |||
| 5 | This guide describes the current state of rust-analyzer as of 2019-01-20 (git | ||
| 6 | tag [guide-2019-01]). Its purpose is to document various problems and | ||
| 7 | architectural solutions related to the problem of building IDE-first compiler | ||
| 8 | for Rust. There is a video version of this guide as well: | ||
| 9 | https://youtu.be/ANKBNiSWyfc. | ||
| 10 | |||
| 11 | [guide-2019-01]: https://github.com/rust-analyzer/rust-analyzer/tree/guide-2019-01 | ||
| 12 | |||
| 13 | ## The big picture | ||
| 14 | |||
| 15 | On the highest possible level, rust-analyzer is a stateful component. A client may | ||
| 16 | apply changes to the analyzer (new contents of `foo.rs` file is "fn main() {}") | ||
| 17 | and it may ask semantic questions about the current state (what is the | ||
| 18 | definition of the identifier with offset 92 in file `bar.rs`?). Two important | ||
| 19 | properties hold: | ||
| 20 | |||
| 21 | * Analyzer does not do any I/O. It starts in an empty state and all input data is | ||
| 22 | provided via `apply_change` API. | ||
| 23 | |||
| 24 | * Only queries about the current state are supported. One can, of course, | ||
| 25 | simulate undo and redo by keeping a log of changes and inverse changes respectively. | ||
| 26 | |||
| 27 | ## IDE API | ||
| 28 | |||
| 29 | To see the bigger picture of how the IDE features works, let's take a look at the [`AnalysisHost`] and | ||
| 30 | [`Analysis`] pair of types. `AnalysisHost` has three methods: | ||
| 31 | |||
| 32 | * `default()` for creating an empty analysis instance | ||
| 33 | * `apply_change(&mut self)` to make changes (this is how you get from an empty | ||
| 34 | state to something interesting) | ||
| 35 | * `analysis(&self)` to get an instance of `Analysis` | ||
| 36 | |||
| 37 | `Analysis` has a ton of methods for IDEs, like `goto_definition`, or | ||
| 38 | `completions`. Both inputs and outputs of `Analysis`' methods are formulated in | ||
| 39 | terms of files and offsets, and **not** in terms of Rust concepts like structs, | ||
| 40 | traits, etc. The "typed" API with Rust specific types is slightly lower in the | ||
| 41 | stack, we'll talk about it later. | ||
| 42 | |||
| 43 | [`AnalysisHost`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/lib.rs#L265-L284 | ||
| 44 | [`Analysis`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/lib.rs#L291-L478 | ||
| 45 | |||
| 46 | The reason for this separation of `Analysis` and `AnalysisHost` is that we want to apply | ||
| 47 | changes "uniquely", but we might also want to fork an `Analysis` and send it to | ||
| 48 | another thread for background processing. That is, there is only a single | ||
| 49 | `AnalysisHost`, but there may be several (equivalent) `Analysis`. | ||
| 50 | |||
| 51 | Note that all of the `Analysis` API return `Cancelable<T>`. This is required to | ||
| 52 | be responsive in an IDE setting. Sometimes a long-running query is being computed | ||
| 53 | and the user types something in the editor and asks for completion. In this | ||
| 54 | case, we cancel the long-running computation (so it returns `Err(Canceled)`), | ||
| 55 | apply the change and execute request for completion. We never use stale data to | ||
| 56 | answer requests. Under the cover, `AnalysisHost` "remembers" all outstanding | ||
| 57 | `Analysis` instances. The `AnalysisHost::apply_change` method cancels all | ||
| 58 | `Analysis`es, blocks until all of them are `Dropped` and then applies changes | ||
| 59 | in-place. This may be familiar to Rustaceans who use read-write locks for interior | ||
| 60 | mutability. | ||
| 61 | |||
| 62 | Next, let's talk about what the inputs to the `Analysis` are, precisely. | ||
| 63 | |||
| 64 | ## Inputs | ||
| 65 | |||
| 66 | Rust Analyzer never does any I/O itself, all inputs get passed explicitly via | ||
| 67 | the `AnalysisHost::apply_change` method, which accepts a single argument, a | ||
| 68 | `AnalysisChange`. [`AnalysisChange`] is a builder for a single change | ||
| 69 | "transaction", so it suffices to study its methods to understand all of the | ||
| 70 | input data. | ||
| 71 | |||
| 72 | [`AnalysisChange`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/lib.rs#L119-L167 | ||
| 73 | |||
| 74 | The `(add|change|remove)_file` methods control the set of the input files, where | ||
| 75 | each file has an integer id (`FileId`, picked by the client), text (`String`) | ||
| 76 | and a filesystem path. Paths are tricky; they'll be explained below, in source roots | ||
| 77 | section, together with the `add_root` method. The `add_library` method allows us to add a | ||
| 78 | group of files which are assumed to rarely change. It's mostly an optimization | ||
| 79 | and does not change the fundamental picture. | ||
| 80 | |||
| 81 | The `set_crate_graph` method allows us to control how the input files are partitioned | ||
| 82 | into compilation unites -- crates. It also controls (in theory, not implemented | ||
| 83 | yet) `cfg` flags. `CrateGraph` is a directed acyclic graph of crates. Each crate | ||
| 84 | has a root `FileId`, a set of active `cfg` flags and a set of dependencies. Each | ||
| 85 | dependency is a pair of a crate and a name. It is possible to have two crates | ||
| 86 | with the same root `FileId` but different `cfg`-flags/dependencies. This model | ||
| 87 | is lower than Cargo's model of packages: each Cargo package consists of several | ||
| 88 | targets, each of which is a separate crate (or several crates, if you try | ||
| 89 | different feature combinations). | ||
| 90 | |||
| 91 | Procedural macros should become inputs as well, but currently they are not | ||
| 92 | supported. Procedural macro will be a black box `Box<dyn Fn(TokenStream) -> TokenStream>` | ||
| 93 | function, and will be inserted into the crate graph just like dependencies. | ||
| 94 | |||
| 95 | Soon we'll talk how we build an LSP server on top of `Analysis`, but first, | ||
| 96 | let's deal with that paths issue. | ||
| 97 | |||
| 98 | |||
| 99 | ## Source roots (a.k.a. "Filesystems are horrible") | ||
| 100 | |||
| 101 | This is a non-essential section, feel free to skip. | ||
| 102 | |||
| 103 | The previous section said that the filesystem path is an attribute of a file, | ||
| 104 | but this is not the whole truth. Making it an absolute `PathBuf` will be bad for | ||
| 105 | several reasons. First, filesystems are full of (platform-dependent) edge cases: | ||
| 106 | |||
| 107 | * it's hard (requires a syscall) to decide if two paths are equivalent | ||
| 108 | * some filesystems are case-sensitive (e.g. on macOS) | ||
| 109 | * paths are not necessary UTF-8 | ||
| 110 | * symlinks can form cycles | ||
| 111 | |||
| 112 | Second, this might hurt reproducibility and hermeticity of builds. In theory, | ||
| 113 | moving a project from `/foo/bar/my-project` to `/spam/eggs/my-project` should | ||
| 114 | not change a bit in the output. However, if the absolute path is a part of the | ||
| 115 | input, it is at least in theory observable, and *could* affect the output. | ||
| 116 | |||
| 117 | Yet another problem is that we really *really* want to avoid doing I/O, but with | ||
| 118 | Rust the set of "input" files is not necessary known up-front. In theory, you | ||
| 119 | can have `#[path="/dev/random"] mod foo;`. | ||
| 120 | |||
| 121 | To solve (or explicitly refuse to solve) these problems rust-analyzer uses the | ||
| 122 | concept of a "source root". Roughly speaking, source roots are the contents of a | ||
| 123 | directory on a file systems, like `/home/matklad/projects/rustraytracer/**.rs`. | ||
| 124 | |||
| 125 | More precisely, all files (`FileId`s) are partitioned into disjoint | ||
| 126 | `SourceRoot`s. Each file has a relative UTF-8 path within the `SourceRoot`. | ||
| 127 | `SourceRoot` has an identity (integer ID). Crucially, the root path of the | ||
| 128 | source root itself is unknown to the analyzer: A client is supposed to maintain a | ||
| 129 | mapping between `SourceRoot` IDs (which are assigned by the client) and actual | ||
| 130 | `PathBuf`s. `SourceRoot`s give a sane tree model of the file system to the | ||
| 131 | analyzer. | ||
| 132 | |||
| 133 | Note that `mod`, `#[path]` and `include!()` can only reference files from the | ||
| 134 | same source root. It is of course is possible to explicitly add extra files to | ||
| 135 | the source root, even `/dev/random`. | ||
| 136 | |||
| 137 | ## Language Server Protocol | ||
| 138 | |||
| 139 | Now let's see how the `Analysis` API is exposed via the JSON RPC based language server protocol. The | ||
| 140 | hard part here is managing changes (which can come either from the file system | ||
| 141 | or from the editor) and concurrency (we want to spawn background jobs for things | ||
| 142 | like syntax highlighting). We use the event loop pattern to manage the zoo, and | ||
| 143 | the loop is the [`main_loop_inner`] function. The [`main_loop`] does a one-time | ||
| 144 | initialization and tearing down of the resources. | ||
| 145 | |||
| 146 | [`main_loop`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L51-L110 | ||
| 147 | [`main_loop_inner`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L156-L258 | ||
| 148 | |||
| 149 | |||
| 150 | Let's walk through a typical analyzer session! | ||
| 151 | |||
| 152 | First, we need to figure out what to analyze. To do this, we run `cargo | ||
| 153 | metadata` to learn about Cargo packages for current workspace and dependencies, | ||
| 154 | and we run `rustc --print sysroot` and scan the "sysroot" (the directory containing the current Rust toolchain's files) to learn about crates like | ||
| 155 | `std`. Currently we load this configuration once at the start of the server, but | ||
| 156 | it should be possible to dynamically reconfigure it later without restart. | ||
| 157 | |||
| 158 | [main_loop.rs#L62-L70](https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L62-L70) | ||
| 159 | |||
| 160 | The [`ProjectModel`] we get after this step is very Cargo and sysroot specific, | ||
| 161 | it needs to be lowered to get the input in the form of `AnalysisChange`. This | ||
| 162 | happens in [`ServerWorldState::new`] method. Specifically | ||
| 163 | |||
| 164 | * Create a `SourceRoot` for each Cargo package and sysroot. | ||
| 165 | * Schedule a filesystem scan of the roots. | ||
| 166 | * Create an analyzer's `Crate` for each Cargo **target** and sysroot crate. | ||
| 167 | * Setup dependencies between the crates. | ||
| 168 | |||
| 169 | [`ProjectModel`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/project_model.rs#L16-L20 | ||
| 170 | [`ServerWorldState::new`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/server_world.rs#L38-L160 | ||
| 171 | |||
| 172 | The results of the scan (which may take a while) will be processed in the body | ||
| 173 | of the main loop, just like any other change. Here's where we handle: | ||
| 174 | |||
| 175 | * [File system changes](https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L194) | ||
| 176 | * [Changes from the editor](https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L377) | ||
| 177 | |||
| 178 | After a single loop's turn, we group the changes into one `AnalysisChange` and | ||
| 179 | [apply] it. This always happens on the main thread and blocks the loop. | ||
| 180 | |||
| 181 | [apply]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/server_world.rs#L216 | ||
| 182 | |||
| 183 | To handle requests, like ["goto definition"], we create an instance of the | ||
| 184 | `Analysis` and [`schedule`] the task (which consumes `Analysis`) on the | ||
| 185 | threadpool. [The task] calls the corresponding `Analysis` method, while | ||
| 186 | massaging the types into the LSP representation. Keep in mind that if we are | ||
| 187 | executing "goto definition" on the threadpool and a new change comes in, the | ||
| 188 | task will be canceled as soon as the main loop calls `apply_change` on the | ||
| 189 | `AnalysisHost`. | ||
| 190 | |||
| 191 | ["goto definition"]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/server_world.rs#L216 | ||
| 192 | [`schedule`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L426-L455 | ||
| 193 | [The task]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop/handlers.rs#L205-L223 | ||
| 194 | |||
| 195 | This concludes the overview of the analyzer's programing *interface*. Next, lets | ||
| 196 | dig into the implementation! | ||
| 197 | |||
| 198 | ## Salsa | ||
| 199 | |||
| 200 | The most straightforward way to implement an "apply change, get analysis, repeat" | ||
| 201 | API would be to maintain the input state and to compute all possible analysis | ||
| 202 | information from scratch after every change. This works, but scales poorly with | ||
| 203 | the size of the project. To make this fast, we need to take advantage of the | ||
| 204 | fact that most of the changes are small, and that analysis results are unlikely | ||
| 205 | to change significantly between invocations. | ||
| 206 | |||
| 207 | To do this we use [salsa]: a framework for incremental on-demand computation. | ||
| 208 | You can skip the rest of the section if you are familiar with rustc's red-green | ||
| 209 | algorithm (which is used for incremental compilation). | ||
| 210 | |||
| 211 | [salsa]: https://github.com/salsa-rs/salsa | ||
| 212 | |||
| 213 | It's better to refer to salsa's docs to learn about it. Here's a small excerpt: | ||
| 214 | |||
| 215 | The key idea of salsa is that you define your program as a set of queries. Every | ||
| 216 | query is used like a function `K -> V` that maps from some key of type `K` to a value | ||
| 217 | of type `V`. Queries come in two basic varieties: | ||
| 218 | |||
| 219 | * **Inputs**: the base inputs to your system. You can change these whenever you | ||
| 220 | like. | ||
| 221 | |||
| 222 | * **Functions**: pure functions (no side effects) that transform your inputs | ||
| 223 | into other values. The results of queries is memoized to avoid recomputing | ||
| 224 | them a lot. When you make changes to the inputs, we'll figure out (fairly | ||
| 225 | intelligently) when we can re-use these memoized values and when we have to | ||
| 226 | recompute them. | ||
| 227 | |||
| 228 | |||
| 229 | For further discussion, its important to understand one bit of "fairly | ||
| 230 | intelligently". Suppose we have two functions, `f1` and `f2`, and one input, | ||
| 231 | `z`. We call `f1(X)` which in turn calls `f2(Y)` which inspects `i(Z)`. `i(Z)` | ||
| 232 | returns some value `V1`, `f2` uses that and returns `R1`, `f1` uses that and | ||
| 233 | returns `O`. Now, let's change `i` at `Z` to `V2` from `V1` and try to compute | ||
| 234 | `f1(X)` again. Because `f1(X)` (transitively) depends on `i(Z)`, we can't just | ||
| 235 | reuse its value as is. However, if `f2(Y)` is *still* equal to `R1` (despite | ||
| 236 | `i`'s change), we, in fact, *can* reuse `O` as result of `f1(X)`. And that's how | ||
| 237 | salsa works: it recomputes results in *reverse* order, starting from inputs and | ||
| 238 | progressing towards outputs, stopping as soon as it sees an intermediate value | ||
| 239 | that hasn't changed. If this sounds confusing to you, don't worry: it is | ||
| 240 | confusing. This illustration by @killercup might help: | ||
| 241 | |||
| 242 | <img alt="step 1" src="https://user-images.githubusercontent.com/1711539/51460907-c5484780-1d6d-11e9-9cd2-d6f62bd746e0.png" width="50%"> | ||
| 243 | |||
| 244 | <img alt="step 2" src="https://user-images.githubusercontent.com/1711539/51460915-c9746500-1d6d-11e9-9a77-27d33a0c51b5.png" width="50%"> | ||
| 245 | |||
| 246 | <img alt="step 3" src="https://user-images.githubusercontent.com/1711539/51460920-cda08280-1d6d-11e9-8d96-a782aa57a4d4.png" width="50%"> | ||
| 247 | |||
| 248 | <img alt="step 4" src="https://user-images.githubusercontent.com/1711539/51460927-d1340980-1d6d-11e9-851e-13c149d5c406.png" width="50%"> | ||
| 249 | |||
| 250 | ## Salsa Input Queries | ||
| 251 | |||
| 252 | All analyzer information is stored in a salsa database. `Analysis` and | ||
| 253 | `AnalysisHost` types are newtype wrappers for [`RootDatabase`] -- a salsa | ||
| 254 | database. | ||
| 255 | |||
| 256 | [`RootDatabase`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/db.rs#L88-L134 | ||
| 257 | |||
| 258 | Salsa input queries are defined in [`FilesDatabase`] (which is a part of | ||
| 259 | `RootDatabase`). They closely mirror the familiar `AnalysisChange` structure: | ||
| 260 | indeed, what `apply_change` does is it sets the values of input queries. | ||
| 261 | |||
| 262 | [`FilesDatabase`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_db/src/input.rs#L150-L174 | ||
| 263 | |||
| 264 | ## From text to semantic model | ||
| 265 | |||
| 266 | The bulk of the rust-analyzer is transforming input text into a semantic model of | ||
| 267 | Rust code: a web of entities like modules, structs, functions and traits. | ||
| 268 | |||
| 269 | An important fact to realize is that (unlike most other languages like C# or | ||
| 270 | Java) there isn't a one-to-one mapping between source code and the semantic model. A | ||
| 271 | single function definition in the source code might result in several semantic | ||
| 272 | functions: for example, the same source file might be included as a module into | ||
| 273 | several crate, or a single "crate" might be present in the compilation DAG | ||
| 274 | several times, with different sets of `cfg`s enabled. The IDE-specific task of | ||
| 275 | mapping source code position into a semantic model is inherently imprecise for | ||
| 276 | this reason, and is handled by the [`source_binder`]. | ||
| 277 | |||
| 278 | [`source_binder`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/source_binder.rs | ||
| 279 | |||
| 280 | The semantic interface is declared in the [`code_model_api`] module. Each entity is | ||
| 281 | identified by an integer ID and has a bunch of methods which take a salsa database | ||
| 282 | as an argument and returns other entities (which are also IDs). Internally, these | ||
| 283 | methods invoke various queries on the database to build the model on demand. | ||
| 284 | Here's [the list of queries]. | ||
| 285 | |||
| 286 | [`code_model_api`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/code_model_api.rs | ||
| 287 | [the list of queries]: https://github.com/rust-analyzer/rust-analyzer/blob/7e84440e25e19529e4ff8a66e521d1b06349c6ec/crates/ra_hir/src/db.rs#L20-L106 | ||
| 288 | |||
| 289 | The first step of building the model is parsing the source code. | ||
| 290 | |||
| 291 | ## Syntax trees | ||
| 292 | |||
| 293 | An important property of the Rust language is that each file can be parsed in | ||
| 294 | isolation. Unlike, say, `C++`, an `include` can't change the meaning of the | ||
| 295 | syntax. For this reason, rust-analyzer can build a syntax tree for each "source | ||
| 296 | file", which could then be reused by several semantic models if this file | ||
| 297 | happens to be a part of several crates. | ||
| 298 | |||
| 299 | The representation of syntax trees that rust-analyzer uses is similar to that of `Roslyn` | ||
| 300 | and Swift's new [libsyntax]. Swift's docs give an excellent overview of the | ||
| 301 | approach, so I skip this part here and instead outline the main characteristics | ||
| 302 | of the syntax trees: | ||
| 303 | |||
| 304 | * Syntax trees are fully lossless. Converting **any** text to a syntax tree and | ||
| 305 | back is a total identity function. All whitespace and comments are explicitly | ||
| 306 | represented in the tree. | ||
| 307 | |||
| 308 | * Syntax nodes have generic `(next|previous)_sibling`, `parent`, | ||
| 309 | `(first|last)_child` functions. You can get from any one node to any other | ||
| 310 | node in the file using only these functions. | ||
| 311 | |||
| 312 | * Syntax nodes know their range (start offset and length) in the file. | ||
| 313 | |||
| 314 | * Syntax nodes share the ownership of their syntax tree: if you keep a reference | ||
| 315 | to a single function, the whole enclosing file is alive. | ||
| 316 | |||
| 317 | * Syntax trees are immutable and the cost of replacing the subtree is | ||
| 318 | proportional to the depth of the subtree. Read Swift's docs to learn how | ||
| 319 | immutable + parent pointers + cheap modification is possible. | ||
| 320 | |||
| 321 | * Syntax trees are build on best-effort basis. All accessor methods return | ||
| 322 | `Option`s. The tree for `fn foo` will contain a function declaration with | ||
| 323 | `None` for parameter list and body. | ||
| 324 | |||
| 325 | * Syntax trees do not know the file they are built from, they only know about | ||
| 326 | the text. | ||
| 327 | |||
| 328 | The implementation is based on the generic [rowan] crate on top of which a | ||
| 329 | [rust-specific] AST is generated. | ||
| 330 | |||
| 331 | [libsyntax]: https://github.com/apple/swift/tree/5e2c815edfd758f9b1309ce07bfc01c4bc20ec23/lib/Syntax | ||
| 332 | [rowan]: https://github.com/rust-analyzer/rowan/tree/100a36dc820eb393b74abe0d20ddf99077b61f88 | ||
| 333 | [rust-specific]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_syntax/src/ast/generated.rs | ||
| 334 | |||
| 335 | The next step in constructing the semantic model is ... | ||
| 336 | |||
| 337 | ## Building a Module Tree | ||
| 338 | |||
| 339 | The algorithm for building a tree of modules is to start with a crate root | ||
| 340 | (remember, each `Crate` from a `CrateGraph` has a `FileId`), collect all `mod` | ||
| 341 | declarations and recursively process child modules. This is handled by the | ||
| 342 | [`module_tree_query`], with two slight variations. | ||
| 343 | |||
| 344 | [`module_tree_query`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/module_tree.rs#L116-L123 | ||
| 345 | |||
| 346 | First, rust-analyzer builds a module tree for all crates in a source root | ||
| 347 | simultaneously. The main reason for this is historical (`module_tree` predates | ||
| 348 | `CrateGraph`), but this approach also enables accounting for files which are not | ||
| 349 | part of any crate. That is, if you create a file but do not include it as a | ||
| 350 | submodule anywhere, you still get semantic completion, and you get a warning | ||
| 351 | about a free-floating module (the actual warning is not implemented yet). | ||
| 352 | |||
| 353 | The second difference is that `module_tree_query` does not *directly* depend on | ||
| 354 | the "parse" query (which is confusingly called `source_file`). Why would calling | ||
| 355 | the parse directly be bad? Suppose the user changes the file slightly, by adding | ||
| 356 | an insignificant whitespace. Adding whitespace changes the parse tree (because | ||
| 357 | it includes whitespace), and that means recomputing the whole module tree. | ||
| 358 | |||
| 359 | We deal with this problem by introducing an intermediate [`submodules_query`]. | ||
| 360 | This query processes the syntax tree and extracts a set of declared submodule | ||
| 361 | names. Now, changing the whitespace results in `submodules_query` being | ||
| 362 | re-executed for a *single* module, but because the result of this query stays | ||
| 363 | the same, we don't have to re-execute [`module_tree_query`]. In fact, we only | ||
| 364 | need to re-execute it when we add/remove new files or when we change mod | ||
| 365 | declarations. | ||
| 366 | |||
| 367 | [`submodules_query`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/module_tree.rs#L41 | ||
| 368 | |||
| 369 | We store the resulting modules in a `Vec`-based indexed arena. The indices in | ||
| 370 | the arena becomes module IDs. And this brings us to the next topic: | ||
| 371 | assigning IDs in the general case. | ||
| 372 | |||
| 373 | ## Location Interner pattern | ||
| 374 | |||
| 375 | One way to assign IDs is how we've dealt with modules: Collect all items into a | ||
| 376 | single array in some specific order and use the index in the array as an ID. The | ||
| 377 | main drawback of this approach is that these IDs are not stable: Adding a new item can | ||
| 378 | shift the IDs of all other items. This works for modules, because adding a module is | ||
| 379 | a comparatively rare operation, but would be less convenient for, for example, | ||
| 380 | functions. | ||
| 381 | |||
| 382 | Another solution here is positional IDs: We can identify a function as "the | ||
| 383 | function with name `foo` in a ModuleId(92) module". Such locations are stable: | ||
| 384 | adding a new function to the module (unless it is also named `foo`) does not | ||
| 385 | change the location. However, such "ID" types ceases to be a `Copy`able integer and in | ||
| 386 | general can become pretty large if we account for nesting (for example: "third parameter of | ||
| 387 | the `foo` function of the `bar` `impl` in the `baz` module"). | ||
| 388 | |||
| 389 | [`LocationInterner`] allows us to combine the benefits of positional and numeric | ||
| 390 | IDs. It is a bidirectional append-only map between locations and consecutive | ||
| 391 | integers which can "intern" a location and return an integer ID back. The salsa | ||
| 392 | database we use includes a couple of [interners]. How to "garbage collect" | ||
| 393 | unused locations is an open question. | ||
| 394 | |||
| 395 | [`LocationInterner`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_db/src/loc2id.rs#L65-L71 | ||
| 396 | [interners]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/db.rs#L22-L23 | ||
| 397 | |||
| 398 | For example, we use `LocationInterner` to assign IDs to definitions of functions, | ||
| 399 | structs, enums, etc. The location, [`DefLoc`] contains two bits of information: | ||
| 400 | |||
| 401 | * the ID of the module which contains the definition, | ||
| 402 | * the ID of the specific item in the modules source code. | ||
| 403 | |||
| 404 | We "could" use a text offset for the location of a particular item, but that would play | ||
| 405 | badly with salsa: offsets change after edits. So, as a rule of thumb, we avoid | ||
| 406 | using offsets, text ranges or syntax trees as keys and values for queries. What | ||
| 407 | we do instead is we store "index" of the item among all of the items of a file | ||
| 408 | (so, a positional based ID, but localized to a single file). | ||
| 409 | |||
| 410 | [`DefLoc`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/ids.rs#L127-L139 | ||
| 411 | |||
| 412 | One thing we've glossed over for the time being is support for macros. We have | ||
| 413 | only proof of concept handling of macros at the moment, but they are extremely | ||
| 414 | interesting from an "assigning IDs" perspective. | ||
| 415 | |||
| 416 | ## Macros and recursive locations | ||
| 417 | |||
| 418 | The tricky bit about macros is that they effectively create new source files. | ||
| 419 | While we can use `FileId`s to refer to original files, we can't just assign them | ||
| 420 | willy-nilly to the pseudo files of macro expansion. Instead, we use a special | ||
| 421 | ID, [`HirFileId`] to refer to either a usual file or a macro-generated file: | ||
| 422 | |||
| 423 | ```rust | ||
| 424 | enum HirFileId { | ||
| 425 | FileId(FileId), | ||
| 426 | Macro(MacroCallId), | ||
| 427 | } | ||
| 428 | ``` | ||
| 429 | |||
| 430 | `MacroCallId` is an interned ID that specifies a particular macro invocation. | ||
| 431 | Its `MacroCallLoc` contains: | ||
| 432 | |||
| 433 | * `ModuleId` of the containing module | ||
| 434 | * `HirFileId` of the containing file or pseudo file | ||
| 435 | * an index of this particular macro invocation in this file (positional id | ||
| 436 | again). | ||
| 437 | |||
| 438 | Note how `HirFileId` is defined in terms of `MacroCallLoc` which is defined in | ||
| 439 | terms of `HirFileId`! This does not recur infinitely though: any chain of | ||
| 440 | `HirFileId`s bottoms out in `HirFileId::FileId`, that is, some source file | ||
| 441 | actually written by the user. | ||
| 442 | |||
| 443 | [`HirFileId`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/ids.rs#L18-L125 | ||
| 444 | |||
| 445 | Now that we understand how to identify a definition, in a source or in a | ||
| 446 | macro-generated file, we can discuss name resolution a bit. | ||
| 447 | |||
| 448 | ## Name resolution | ||
| 449 | |||
| 450 | Name resolution faces the same problem as the module tree: if we look at the | ||
| 451 | syntax tree directly, we'll have to recompute name resolution after every | ||
| 452 | modification. The solution to the problem is the same: We [lower] the source code of | ||
| 453 | each module into a position-independent representation which does not change if | ||
| 454 | we modify bodies of the items. After that we [loop] resolving all imports until | ||
| 455 | we've reached a fixed point. | ||
| 456 | |||
| 457 | [lower]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/nameres/lower.rs#L113-L117 | ||
| 458 | [loop]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/nameres.rs#L186-L196 | ||
| 459 | |||
| 460 | And, given all our preparation with IDs and a position-independent representation, | ||
| 461 | it is satisfying to [test] that typing inside function body does not invalidate | ||
| 462 | name resolution results. | ||
| 463 | |||
| 464 | [test]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/nameres/tests.rs#L376 | ||
| 465 | |||
| 466 | An interesting fact about name resolution is that it "erases" all of the | ||
| 467 | intermediate paths from the imports: in the end, we know which items are defined | ||
| 468 | and which items are imported in each module, but, if the import was `use | ||
| 469 | foo::bar::baz`, we deliberately forget what modules `foo` and `bar` resolve to. | ||
| 470 | |||
| 471 | To serve "goto definition" requests on intermediate segments we need this info | ||
| 472 | in the IDE, however. Luckily, we need it only for a tiny fraction of imports, so we just ask | ||
| 473 | the module explicitly, "What does the path `foo::bar` resolve to?". This is a | ||
| 474 | general pattern: we try to compute the minimal possible amount of information | ||
| 475 | during analysis while allowing IDE to ask for additional specific bits. | ||
| 476 | |||
| 477 | Name resolution is also a good place to introduce another salsa pattern used | ||
| 478 | throughout the analyzer: | ||
| 479 | |||
| 480 | ## Source Map pattern | ||
| 481 | |||
| 482 | Due to an obscure edge case in completion, IDE needs to know the syntax node of | ||
| 483 | an use statement which imported the given completion candidate. We can't just | ||
| 484 | store the syntax node as a part of name resolution: this will break | ||
| 485 | incrementality, due to the fact that syntax changes after every file | ||
| 486 | modification. | ||
| 487 | |||
| 488 | We solve this problem during the lowering step of name resolution. The lowering | ||
| 489 | query actually produces a *pair* of outputs: `LoweredModule` and [`SourceMap`]. | ||
| 490 | The `LoweredModule` module contains [imports], but in a position-independent form. | ||
| 491 | The `SourceMap` contains a mapping from position-independent imports to | ||
| 492 | (position-dependent) syntax nodes. | ||
| 493 | |||
| 494 | The result of this basic lowering query changes after every modification. But | ||
| 495 | there's an intermediate [projection query] which returns only the first | ||
| 496 | position-independent part of the lowering. The result of this query is stable. | ||
| 497 | Naturally, name resolution [uses] this stable projection query. | ||
| 498 | |||
| 499 | [imports]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/nameres/lower.rs#L52-L59 | ||
| 500 | [`SourceMap`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/nameres/lower.rs#L52-L59 | ||
| 501 | [projection query]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/nameres/lower.rs#L97-L103 | ||
| 502 | [uses]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/query_definitions.rs#L49 | ||
| 503 | |||
| 504 | ## Type inference | ||
| 505 | |||
| 506 | First of all, implementation of type inference in rust-analyzer was spearheaded | ||
| 507 | by [@flodiebold]. [#327] was an awesome Christmas present, thank you, Florian! | ||
| 508 | |||
| 509 | Type inference runs on per-function granularity and uses the patterns we've | ||
| 510 | discussed previously. | ||
| 511 | |||
| 512 | First, we [lower the AST] of a function body into a position-independent | ||
| 513 | representation. In this representation, each expression is assigned a | ||
| 514 | [positional ID]. Alongside the lowered expression, [a source map] is produced, | ||
| 515 | which maps between expression ids and original syntax. This lowering step also | ||
| 516 | deals with "incomplete" source trees by replacing missing expressions by an | ||
| 517 | explicit `Missing` expression. | ||
| 518 | |||
| 519 | Given the lowered body of the function, we can now run [type inference] and | ||
| 520 | construct a mapping from `ExprId`s to types. | ||
| 521 | |||
| 522 | [@flodiebold]: https://github.com/flodiebold | ||
| 523 | [#327]: https://github.com/rust-analyzer/rust-analyzer/pull/327 | ||
| 524 | [lower the AST]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/expr.rs | ||
| 525 | [positional ID]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/expr.rs#L13-L15 | ||
| 526 | [a source map]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/expr.rs#L41-L44 | ||
| 527 | [type inference]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_hir/src/ty.rs#L1208-L1223 | ||
| 528 | |||
| 529 | ## Tying it all together: completion | ||
| 530 | |||
| 531 | To conclude the overview of the rust-analyzer, let's trace the request for | ||
| 532 | (type-inference powered!) code completion! | ||
| 533 | |||
| 534 | We start by [receiving a message] from the language client. We decode the | ||
| 535 | message as a request for completion and [schedule it on the threadpool]. This is | ||
| 536 | the also place where we [catch] canceled errors if, immediately after completion, the | ||
| 537 | client sends some modification. | ||
| 538 | |||
| 539 | In [the handler] we a deserialize LSP request into the rust-analyzer specific data | ||
| 540 | types (by converting a file url into a numeric `FileId`), [ask analysis for | ||
| 541 | completion] and serializer results to LSP. | ||
| 542 | |||
| 543 | The [completion implementation] is finally the place where we start doing the actual | ||
| 544 | work. The first step is to collect the `CompletionContext` -- a struct which | ||
| 545 | describes the cursor position in terms of Rust syntax and semantics. For | ||
| 546 | example, `function_syntax: Option<&'a ast::FnDef>` stores a reference to | ||
| 547 | enclosing function *syntax*, while `function: Option<hir::Function>` is the | ||
| 548 | `Def` for this function. | ||
| 549 | |||
| 550 | To construct the context, we first do an ["IntelliJ Trick"]: we insert a dummy | ||
| 551 | identifier at the cursor's position and parse this modified file, to get a | ||
| 552 | reasonably looking syntax tree. Then we do a bunch of "classification" routines | ||
| 553 | to figure out the context. For example, we [find an ancestor `fn` node] and we get a | ||
| 554 | [semantic model] for it (using the lossy `source_binder` infrastructure). | ||
| 555 | |||
| 556 | The second step is to run a [series of independent completion routines]. Let's | ||
| 557 | take a closer look at [`complete_dot`], which completes fields and methods in | ||
| 558 | `foo.bar|`. First we extract a semantic function and a syntactic receiver | ||
| 559 | expression out of the `Context`. Then we run type-inference for this single | ||
| 560 | function and map our syntactic expression to `ExprId`. Using the ID, we figure | ||
| 561 | out the type of the receiver expression. Then we add all fields & methods from | ||
| 562 | the type to completion. | ||
| 563 | |||
| 564 | [receiving a message]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L203 | ||
| 565 | [schedule it on the threadpool]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L428 | ||
| 566 | [catch]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L436-L442 | ||
| 567 | [the handler]: https://salsa.zulipchat.com/#narrow/stream/181542-rfcs.2Fsalsa-query-group/topic/design.20next.20steps | ||
| 568 | [ask analysis for completion]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/lib.rs#L439-L444 | ||
| 569 | [completion implementation]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion.rs#L46-L62 | ||
| 570 | [`CompletionContext`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion/completion_context.rs#L14-L37 | ||
| 571 | ["IntelliJ Trick"]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion/completion_context.rs#L72-L75 | ||
| 572 | [find an ancestor `fn` node]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion/completion_context.rs#L116-L120 | ||
| 573 | [semantic model]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion/completion_context.rs#L123 | ||
| 574 | [series of independent completion routines]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion.rs#L52-L59 | ||
| 575 | [`complete_dot`]: https://github.com/rust-analyzer/rust-analyzer/blob/guide-2019-01/crates/ra_ide_api/src/completion/complete_dot.rs#L6-L22 | ||
diff --git a/docs/dev/lsp-features.md b/docs/dev/lsp-features.md new file mode 100644 index 000000000..212d132ee --- /dev/null +++ b/docs/dev/lsp-features.md | |||
| @@ -0,0 +1,74 @@ | |||
| 1 | # Supported LSP features | ||
| 2 | |||
| 3 | This list documents LSP features, supported by rust-analyzer. | ||
| 4 | |||
| 5 | ## General | ||
| 6 | - [x] [initialize](https://microsoft.github.io/language-server-protocol/specification#initialize) | ||
| 7 | - [x] [initialized](https://microsoft.github.io/language-server-protocol/specification#initialized) | ||
| 8 | - [x] [shutdown](https://microsoft.github.io/language-server-protocol/specification#shutdown) | ||
| 9 | - [ ] [exit](https://microsoft.github.io/language-server-protocol/specification#exit) | ||
| 10 | - [x] [$/cancelRequest](https://microsoft.github.io/language-server-protocol/specification#cancelRequest) | ||
| 11 | |||
| 12 | ## Workspace | ||
| 13 | - [ ] [workspace/workspaceFolders](https://microsoft.github.io/language-server-protocol/specification#workspace_workspaceFolders) | ||
| 14 | - [ ] [workspace/didChangeWorkspaceFolders](https://microsoft.github.io/language-server-protocol/specification#workspace_didChangeWorkspaceFolders) | ||
| 15 | - [x] [workspace/didChangeConfiguration](https://microsoft.github.io/language-server-protocol/specification#workspace_didChangeConfiguration) | ||
| 16 | - [ ] [workspace/configuration](https://microsoft.github.io/language-server-protocol/specification#workspace_configuration) | ||
| 17 | - [x] [workspace/didChangeWatchedFiles](https://microsoft.github.io/language-server-protocol/specification#workspace_didChangeWatchedFiles) | ||
| 18 | - [x] [workspace/symbol](https://microsoft.github.io/language-server-protocol/specification#workspace_symbol) | ||
| 19 | - [x] [workspace/executeCommand](https://microsoft.github.io/language-server-protocol/specification#workspace_executeCommand) | ||
| 20 | - `apply_code_action` | ||
| 21 | - [ ] [workspace/applyEdit](https://microsoft.github.io/language-server-protocol/specification#workspace_applyEdit) | ||
| 22 | |||
| 23 | ## Text Synchronization | ||
| 24 | - [x] [textDocument/didOpen](https://microsoft.github.io/language-server-protocol/specification#textDocument_didOpen) | ||
| 25 | - [x] [textDocument/didChange](https://microsoft.github.io/language-server-protocol/specification#textDocument_didChange) | ||
| 26 | - [ ] [textDocument/willSave](https://microsoft.github.io/language-server-protocol/specification#textDocument_willSave) | ||
| 27 | - [ ] [textDocument/willSaveWaitUntil](https://microsoft.github.io/language-server-protocol/specification#textDocument_willSaveWaitUntil) | ||
| 28 | - [x] [textDocument/didSave](https://microsoft.github.io/language-server-protocol/specification#textDocument_didSave) | ||
| 29 | - [x] [textDocument/didClose](https://microsoft.github.io/language-server-protocol/specification#textDocument_didClose) | ||
| 30 | |||
| 31 | ## Diagnostics | ||
| 32 | - [x] [textDocument/publishDiagnostics](https://microsoft.github.io/language-server-protocol/specification#textDocument_publishDiagnostics) | ||
| 33 | |||
| 34 | ## Lanuguage Features | ||
| 35 | - [x] [textDocument/completion](https://microsoft.github.io/language-server-protocol/specification#textDocument_completion) | ||
| 36 | - open close: false | ||
| 37 | - change: Full | ||
| 38 | - will save: false | ||
| 39 | - will save wait until: false | ||
| 40 | - save: false | ||
| 41 | - [x] [completionItem/resolve](https://microsoft.github.io/language-server-protocol/specification#completionItem_resolve) | ||
| 42 | - resolve provider: none | ||
| 43 | - trigger characters: `:`, `.` | ||
| 44 | - [x] [textDocument/hover](https://microsoft.github.io/language-server-protocol/specification#textDocument_hover) | ||
| 45 | - [x] [textDocument/signatureHelp](https://microsoft.github.io/language-server-protocol/specification#textDocument_signatureHelp) | ||
| 46 | - trigger characters: `(`, `,`, `)` | ||
| 47 | - [ ] [textDocument/declaration](https://microsoft.github.io/language-server-protocol/specification#textDocument_declaration) | ||
| 48 | - [x] [textDocument/definition](https://microsoft.github.io/language-server-protocol/specification#textDocument_definition) | ||
| 49 | - [ ] [textDocument/typeDefinition](https://microsoft.github.io/language-server-protocol/specification#textDocument_typeDefinition) | ||
| 50 | - [x] [textDocument/implementation](https://microsoft.github.io/language-server-protocol/specification#textDocument_implementation) | ||
| 51 | - [x] [textDocument/references](https://microsoft.github.io/language-server-protocol/specification#textDocument_references) | ||
| 52 | - [x] [textDocument/documentHighlight](https://microsoft.github.io/language-server-protocol/specification#textDocument_documentHighlight) | ||
| 53 | - [x] [textDocument/documentSymbol](https://microsoft.github.io/language-server-protocol/specification#textDocument_documentSymbol) | ||
| 54 | - [x] [textDocument/codeAction](https://microsoft.github.io/language-server-protocol/specification#textDocument_codeAction) | ||
| 55 | - rust-analyzer.syntaxTree | ||
| 56 | - rust-analyzer.extendSelection | ||
| 57 | - rust-analyzer.matchingBrace | ||
| 58 | - rust-analyzer.parentModule | ||
| 59 | - rust-analyzer.joinLines | ||
| 60 | - rust-analyzer.run | ||
| 61 | - rust-analyzer.analyzerStatus | ||
| 62 | - [x] [textDocument/codeLens](https://microsoft.github.io/language-server-protocol/specification#textDocument_codeLens) | ||
| 63 | - [ ] [textDocument/documentLink](https://microsoft.github.io/language-server-protocol/specification#codeLens_resolve) | ||
| 64 | - [ ] [documentLink/resolve](https://microsoft.github.io/language-server-protocol/specification#documentLink_resolve) | ||
| 65 | - [ ] [textDocument/documentColor](https://microsoft.github.io/language-server-protocol/specification#textDocument_documentColor) | ||
| 66 | - [ ] [textDocument/colorPresentation](https://microsoft.github.io/language-server-protocol/specification#textDocument_colorPresentation) | ||
| 67 | - [x] [textDocument/formatting](https://microsoft.github.io/language-server-protocol/specification#textDocument_formatting) | ||
| 68 | - [ ] [textDocument/rangeFormatting](https://microsoft.github.io/language-server-protocol/specification#textDocument_rangeFormatting) | ||
| 69 | - [x] [textDocument/onTypeFormatting](https://microsoft.github.io/language-server-protocol/specification#textDocument_onTypeFormatting) | ||
| 70 | - first trigger character: `=` | ||
| 71 | - more trigger character `.` | ||
| 72 | - [x] [textDocument/rename](https://microsoft.github.io/language-server-protocol/specification#textDocument_rename) | ||
| 73 | - [x] [textDocument/prepareRename](https://microsoft.github.io/language-server-protocol/specification#textDocument_prepareRename) | ||
| 74 | - [x] [textDocument/foldingRange](https://microsoft.github.io/language-server-protocol/specification#textDocument_foldingRange) | ||